
The AI-Native SIEM Must Be Programmable


Three different users will touch your security platform this week: a person clicking through the UI, a script running in CI, and an agent deciding what to query next during an investigation. Most products rush the API to build a pretty user interface and only think about programmatic access later, but that doesn't work if agents are included in your user base.
When an agent investigates an alert, it doesn't read your docs or sit through a demo. It reads the list of tools it has, picks one, and calls it. If your platform can't hand an agent a clean list of actions with clear descriptions, the agent can't use it. The same goes for the engineer who wants to manage detections from a Git repo instead of a web form. When the UI is the only complete interface, everything else is a second-class workaround that drifts out of date.
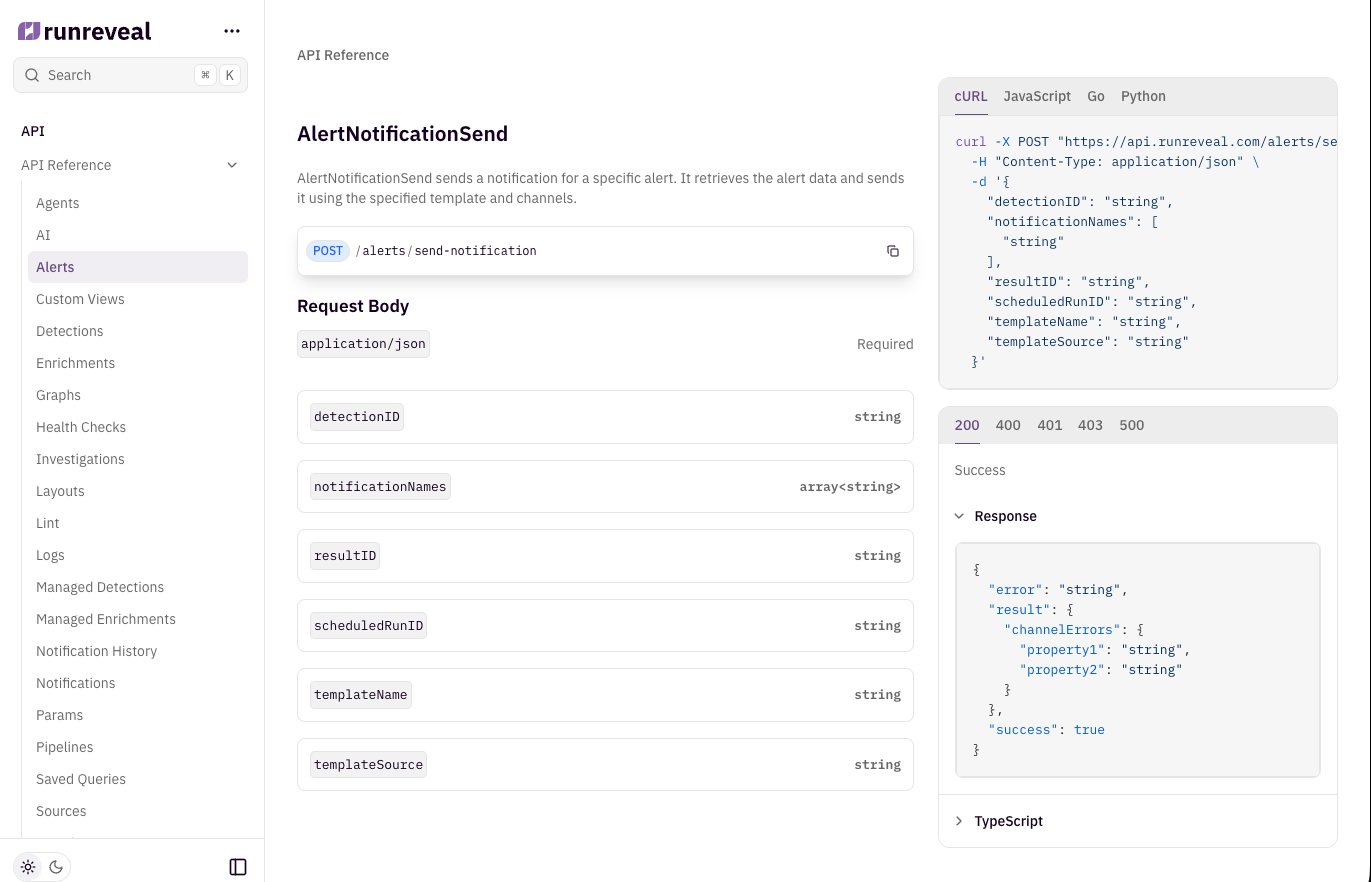
Today we published the RunReveal API reference in our docs. It documents every endpoint, with request parameters, body schemas, and response shapes, grouped by resource. It's the same surface our own UI, CLI, and AI agent run on.
One definition, every interface
Plenty of security products have a REST API. What makes ours worth writing about is that it's generated from the same code that runs the product, so it can't quietly fall out of date.
The idea came from my time building on Ruby on Rails, years ago. A Rails controller action prepares its data once, and respond_to hands that same result to whichever representation the client asked for: an HTML view for a browser, JSON for an API client, XML for an older integration. You write the logic a single time and the framework renders it for each format. The controller doesn't care who's calling; the format layer figures out how to answer.
Go gives you none of that out of the box, so we built our own framework to be able to generate these programmatically. Every endpoint in RunReveal is defined once. From that single definition we generate the REST route, the OpenAPI specification behind these docs, the CLI commands, and the tools the agent can invoke over MCP. None of these can drift, because there's nothing to keep in sync by hand. The reference provided above is built from the same router that serves production traffic. Change an endpoint and the spec changes with it.
Hand-maintained or agent-generated API docs lie. They start accurate, then fall behind the code one undocumented parameter at a time, until nobody trusts them and everybody reads the source instead; or worse, they learn by failing to use your API effectively. Generating the docs from the running server removes that failure mode. If the docs are wrong, the product is wrong, and we'd catch it in testing.
Every API call is also a tool call
Every endpoint includes a written description of what it does and how to use it well, and we write that description with agents in mind as much as the people reading the docs. The query endpoint, for instance, tells the caller to filter on indexed columns and keep result limits small while exploring. That text isn't documentation we wrote a second time. It's the exact string the agent sees when it lists its tools, and the exact text rendered in the reference.
So when our AI agent runs an investigation, it calls the endpoints you'd call from a script. The query it runs to pull authentication logs is the same query you can run with curl, from the CLI, or inside a scheduled detection. Because an agent planning a SQL query and an engineer paging through results go through the same door, anything the agent can do you can audit, reproduce, and automate yourself.
Detection as code, with the UI intact
Programmable does not mean headless. A good API and a good interface solve different problems, and you should get both.
Write a detection as a Sigma rule in a Git repo, review it in a pull request, and ship it through CI. Or build the same detection in the UI, see its fields laid out in a form, watch it match live events, and tune the logic before you save. Both paths write to the same API and produce the same object. The code-first team and the click-first analyst manage one set of detections, not two copies waiting to disagree.
That symmetry is the whole point. Configuration that a program can write, a human can see and adjust, and an agent can reason about. The visualization isn't a separate product layered on top of the data; it reads and writes through the same endpoints everything else uses.
A security platform built this way stays honest: the interface a person trusts and the interface a machine calls are the same code, so they tell the same story. Browse the API reference, point an agent at it, or wire it into your pipeline; it's the same RunReveal either way.
TL/DR: If your team can manage detections from a Git repo and your AI agent can call the same endpoints your analysts use, you're in good shape. If not, RunReveal is worth a look.