
There's a problem with SIEM. Why Johnny Can't Detect.


SIEM is hot right now! Cisco acquired Splunk. Exabeam and LogRhythm merged. Palo Alto acquired QRadar from IBM. That's a lot of action given SIEM is a mature market. There's just one big problem... nearly everyone is still unhappy with their SIEM.
Alert fatigue, months long setup, dozens of vendors to help with all aspects of detection, and don't even get me started with the costs. We can't just stop logging and alerting, but there seems to be a unanimous thinking that what we're doing currently in the industry reached it's end-of-life a few years ago.
The outcome of this is that SIEM vendors are amongst the most disliked vendors in any security budget. One observation we've made is that many of the leading SIEM companies started as database companies first and became security companies second. These businesses focus on their customers storing more logs this year than last year, but this metric doesn't indicate how much value their customers are getting from the product, and we think that's where the problem begins.
SIEM is dominated by database companies
Once Splunk was launched in 2004 they found immediate success and product market fit, but not with CISO buyers. In fact, the CISO position was pretty uncommon in 2004. Splunk found success with IT administrators who wanted to debug when their systems broke. Logs would be forwarded to a centralized Splunk server, and that one interface could be used to look for problems.
This naturally developed into being useful for security logs too. Companies want to collect security logs centrally, look for anomalous activity indicating a compromise, and be able to spring into action when they notice an incident.
This path of originally solving for IT logs and then specializing in security logs became a common path. According to our research ArcSight, SumoLogic, Splunk, Elastic, LogRhythm, and Graylog all began as databases designed for generalized logging workloads and worked their way into security after the fact.

At it's surface the security use cases and system observability use cases sound remarkably similar but there are subtle differences. Security teams need to store their logs for more than a year and in most cases operational data isn't very relevant after more than a few weeks. Additionally, security monitoring systems log all activity and look for anomalies compared with operational monitoring which log errors when things go wrong but generally emit only metrics and a small amount of logs when things are operating properly.
All of those listed vendors may have built amazing technology but "detection" isn't what that technology was originally designed for. Dozens of bolt on vendors try to fix these issues and largely fail. Are there different ways we should be thinking about detection entirely?
SIEM is more than a database
RunReveal's interpretation of this problem begins with what we hear are the biggest problems in detection. Alert fatigue, difficult management, and enormous costs. How can we increase the signal, process more logs, and make the entire process much cheaper?
Contextualization
As soon as we receive a log we work to begin contextualizing it. There are multiple stages of this but it encompasses enrichments, signature based detections with sigma, filtering, and then finally a decision about where the log belongs.
Logs that seem less important are still processed, normalized, and enriched, but are then sent to low cost blob storage where they are available to be re-ingested and re-processed if a security incident ever requires it.
Logs that are high value, match detections you've written, or come from more important sources can be sent directly to your higher cost SIEM.
A key point is that a low-value log and high-value log might be emitted from the same log source at the same time, and the ability to easily route, make decisions, and re-ingest logs needs to be on a per-log basis.
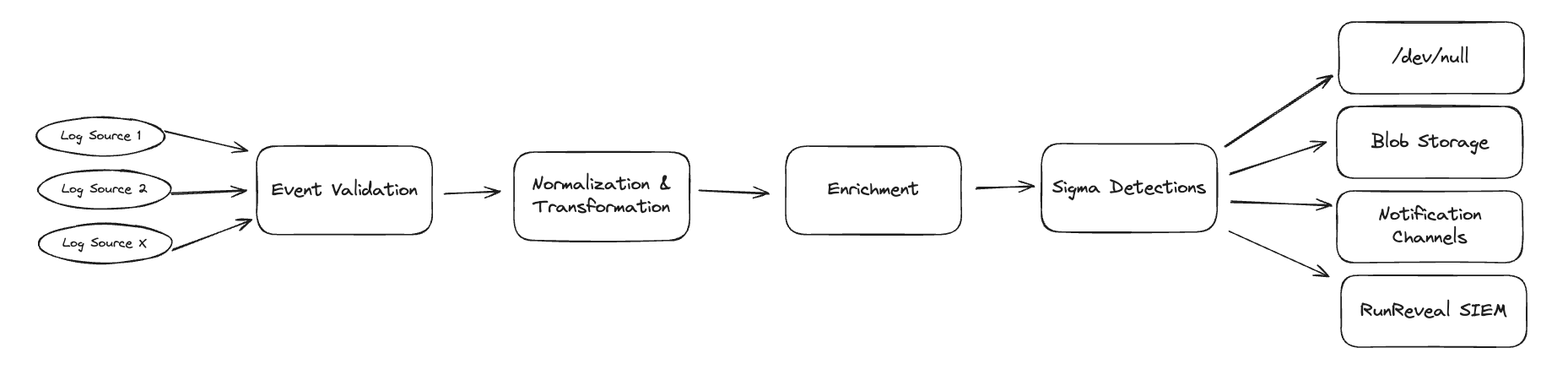
This step is necessary, performed on the stream of logs we receive, and can inexpensively scale the collection of information and metadata from your logs to even the biggest data-sets.
Correlation
No single log will tell you when you're compromised. Once we've determined what logs are important and what logs aren't, we help you label the important logs and group them together into attack patterns. This is usually called "correlation" in the world of SIEM, but most SIEM companies can't tell you how they do it.
We wrote about our simple correlation engine a few months ago, and how it can be used to spot patterns of activities, important changes, and leveraged for building flexible custom alerts. Databases are actually very good at this kind of task but the right data model can really help with simplifying this process.

We store all of the logs, signals, and alerts in separate tables that help our customers group and contextualize any detection results with very simple queries.
Searching logs, writing detections, maintaining detections with detection as code, and keeping your database in your own account or completely managed by us a breeze.
Incident response
Once something bad happens you need the ability to investigate it. RunReveal can help you customize how long data should be stored in your database, and is working on re-ingesting your critical data back into RunReveal when the logs you care about are expired.
We want our customers to be able to store their "rainy day" logs in low cost object storage and still make those logs usable when an incident occurs. Our destinations product works seamlessly for writing your fully enriched logs to a blob destination, and those logs need to just as seamlessly be re-ingested when you need them no matter how old they are.
RunReveal is working on the capability to quickly and easily re-ingest data that we previously processed and should be releasing it soon.
Takeaways
No database company can do all of these things because they aren't incentivized to store less data or process data in smarter ways. Some companies are attempting to cobble this architecture together with multiple vendors but interoperability, set up challenges, data-model mismatches, and budgetary constraints make this difficult to realize for even the most sophisticated teams.
We think that many of the problems we're dealing with today are tied to "the old way of doing things", and being successful as a detection team requires careful consideration of your end-to-end detection strategy and what data architecture helps you achieve that.
We built RunReveal with this in mind for the biggest data sets. We started by first asking "What problems do security teams have with detection?" and then "What's the best way to solve those problems?". The results have been fantastic and we have the scale to process millions of logs per second and help with each step of the detection process.
If you want to see our product in action, or exchange notes on security engineering, feel free to reach out!