
The history of centralized logging
To understand the present and future of logging, we need to first understand the past.


In the 70s and 80s some people had the idea to start letting computers talk to one another and ever since then engineers have been tirelessly working to keep the conversation going. When the programmers of the 70s made the decision to start doing this, we began exponentially increasing the number of security and reliability issues, and introduced an entirely new dimension to build and repair: the network.
Log management is essential to understanding the complexity of managing networked computers. To cope with these new challenges, a variety of protocols, products and solutions have been developed to help collect, store, and understand computer logs.
To understand centralized logging today it's necessary to first understand the prior art of where we've come from and consciously acknowledge what problems we're attempting to solve with this technology. Like most technology, logging paradigms have gone through various phases; each phase accelerating and shortening in length over time.
Perhaps unsurprisingly, almost as soon as networked computers were developed people started sending logs over the network.
The early days of syslog
In the 1980s, Eric Allman was a programmer working at Berkeley. An early pioneer in computer networking, he wrote delivermail for ARPANET. When Berkeley and AT&T labs started connecting Unix computers together, he converted delivermail to the Unix-compatible sendmail email server which eventually earned him a spot in the Internet hall of fame.
One of his lesser known accomplishments which happened around the same was creating syslog, which soon became integrated with sendmail and was used for audit logging and debugging of operational issues. At the time, syslog was the complete package. It was a daemon for receiving logs over the network, a protocol for sending them, and quickly became the de-facto standard for all centralized logging.

Syslog wasn't formally standardized until 2001 when RFC 3164 came out, and in 2009 a second iteration of the standard was published as RFC 5424. Additionally, several follow-on RFCs added support for secure transport and TCP.
The simplicity of the syslog format is likely one of the reasons for it's success. Looking at its wire format shows the components of a syslog message and how it's transmitted. It contains three parts, the PRI, the HEADER, and the MSG.

PRI contains the "Facility" and the "Severity". It's a 1-3 digit number surrounded by a less-than and greater-than sign. Facility is one of 23 predefined codes representing the type of message that is being sent. Severity is a number 0-7 where 0 is Emergency and 7 is Debug. PRI is calculated by multiplying facility by 8 (shift bits left 3), then adding the severity (a 3 bit number).
HEADER contains a "timestamp" and a "host identifier". Timestamp must be in the Mmm dd hh:mm:ss format and is specified to be the local timestamp of the host. The original spec (RFC3164) doesn't say anything about including timezone information, but of course this was addressed in RFC 5424. The new spec updates the timestamp to be the more sane RFC3339 format. Hostname can either be an IP address or a hostname. The two components are delimited by a space.
MSG contains a "tag" and a "content". Tag is an alphanumeric name of the program that generated the message, and any non-alphanumeric will denote the end of the tag. It's at most 32 characters long. Content is the actual meat of the message. It can be freeform or structured.
A few fields, some clever multiplication, and syslog became the de-facto standard for transferring logs over the network. At some point in the late 90s/early 00s, the average size of corporate computer networks grew beyond what a syslog server could handle alone. At larger scales, a new set of tools to search, alert, and visualize your logs became necessary.
I got 99 problems and logging is all of them
As the web began to enter it's awkward teens in the early 00s, Jay-Z and the unmistakable whirring and beeping of the dial up modem became the soundtrack of the era defined by flash games, geocities, myspace, anonymous chatrooms, pop-ups, spam, and the birth of a new global language: Internet memes. With this mind bending new form of entertainment and communication came the mad rush to bring the world online, and with it a torrent of internet traffic that forced businesses to reconsider how to manage their IT infrastructure.
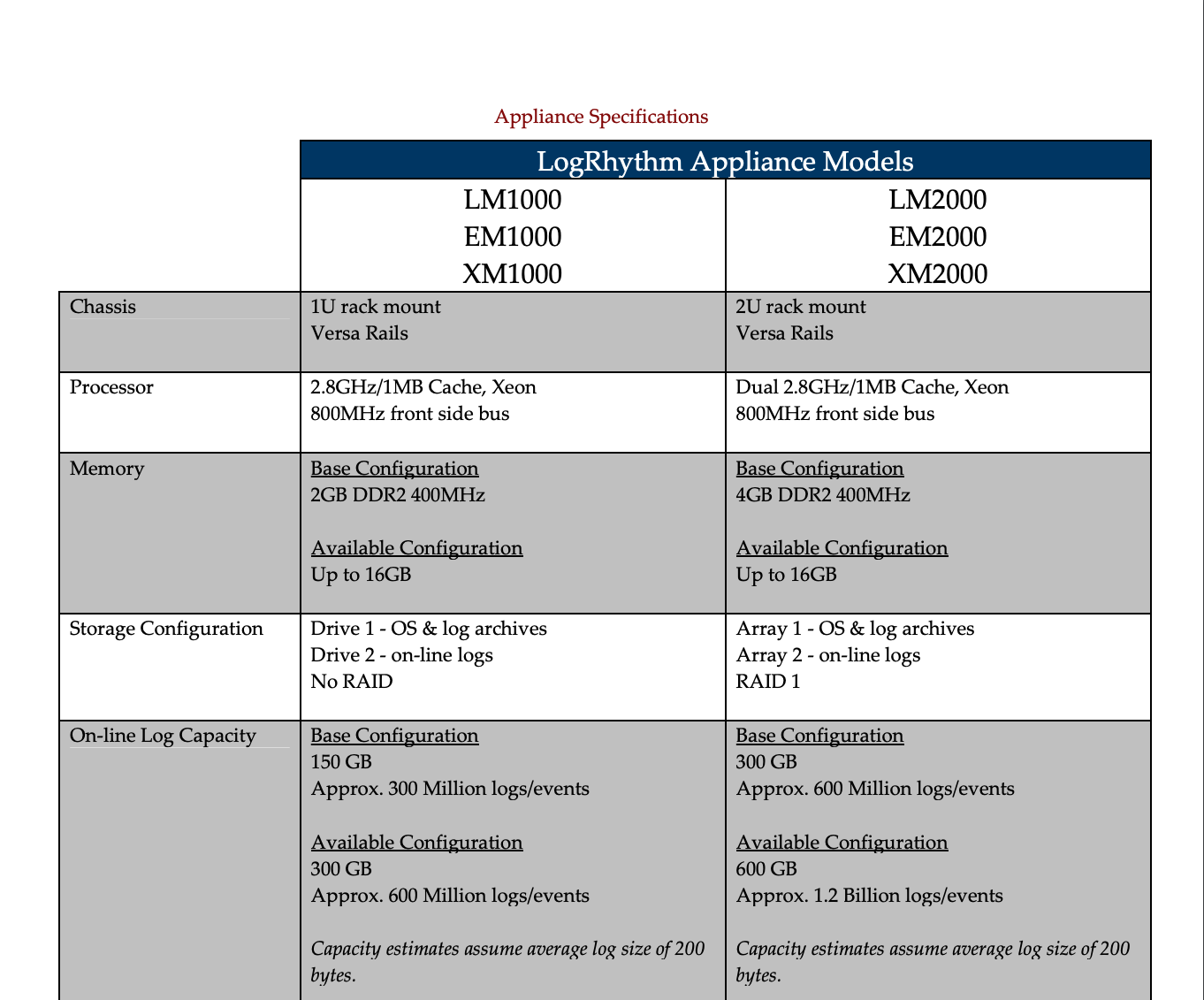
With more servers came more logs and new challenges in understanding what's actually happening across the whole fleet of machines. To address this, companies like Splunk and LogRhythm (both formed in 2003), built solutions to handle the sprawling data problem.
Splunk approached the problem from the management and operations perspective, aiming to build the "Google for log files". They recognized the difficulties faced by companies and helped them collect, aggregate and visualize their infrastructure in a way previously unseen in the marketplace. Their observability tooling was unmatched at the time.
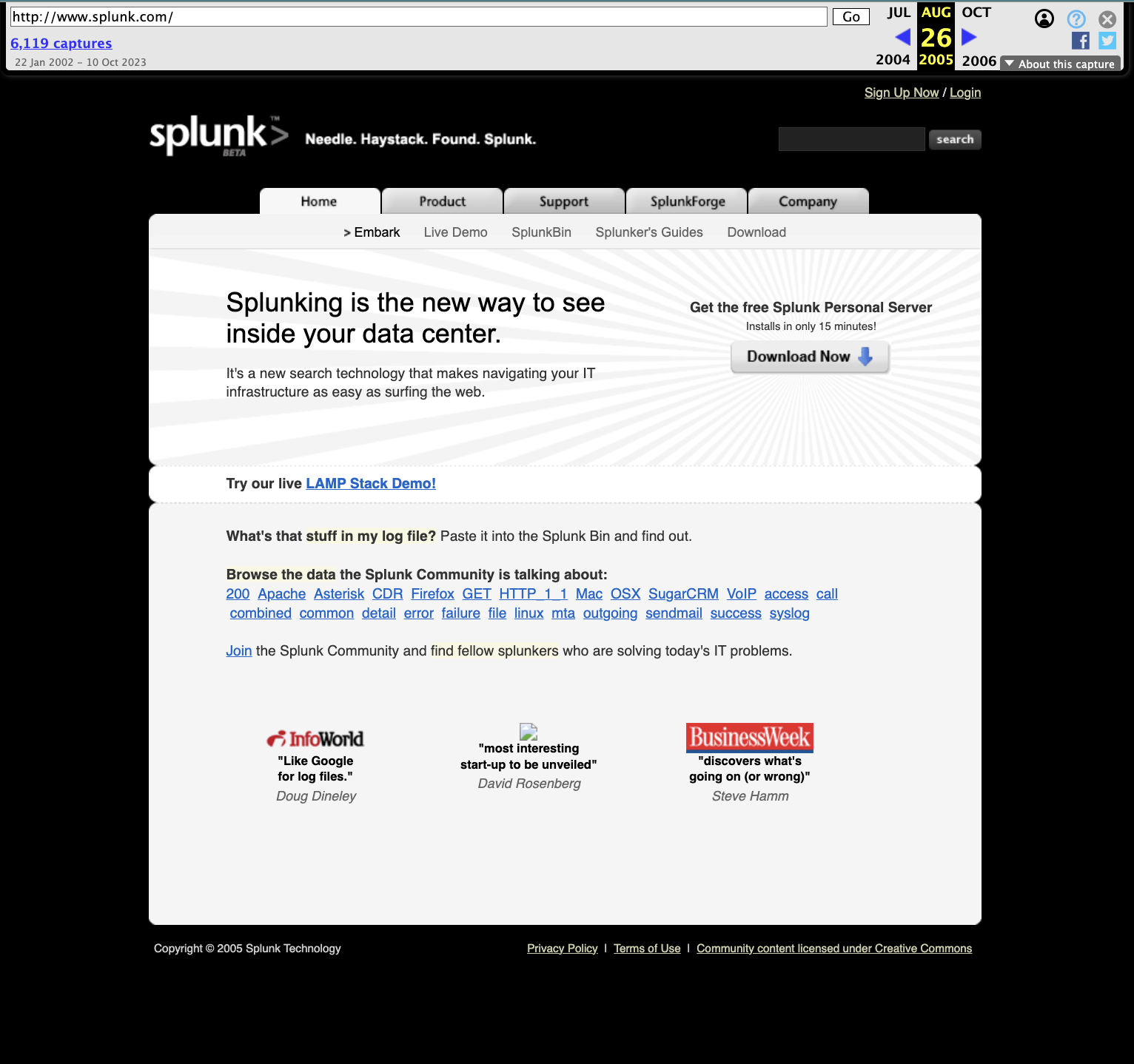
LogRhythm came from the security operations angle and was one of the defining companies in the SIEM (Security Information and Event Managment) market space. They built their product with intrusion detection as well as post-compromise forensics in mind, and captured the security focused market.
Both companies achieved major success for wrangling control over the sprawling mess of logs being produced. As the industry at large was figuring out the finer bits of running software across many computers, other companies were figuring out how to best offer servers-as-a-service. Most notably, the largest online retailer at the time had decided to start renting it's infrastructure to the rest of the world: Amazon Web Services. The world of computing was forever changed when it entered the new era of Cloud Computing.
It's raining logs!
It goes without saying for those who have been working in the industry, but the rise of virtualization and the cloud greatly accelerated software engineer's productivity. No longer were they responsible for their own relatively fallible copper and silicon pizza boxes, now they could focus more on building software and less on replacing hard drives.
Naturally, a new paradigm in software architecture brought with it solutions to fit the new problems. You couldn't exactly plug your Splunk or LogRhythm log servers from yesteryear into the new cloud platforms and start receiving logs without considerable effort.
During this period Sumo Logic, Datadog, Elastic and others rose to produce new software services which were more tightly integrated with the APIs and workflows of the cloud than their predecessors.
In order to ensure customers trusted that their vendors could provide high levels of uptime and stability, these emerging companies had to architect their infrastructure using relatively new (to the industry, not academia) distributed systems approaches to software design. This key development meant that they could pretty much scale infinitely as far as their customers were concerned and if their pockets were deep enough.
Each of these new contenders thrived in the new cloud world. Datadog came from the observability focused market, and didn't initially handle logging instead opting for ingesting events, which are kinda like super logs, as they represent major changes like a software version upgrade. Datadog eventually added logs in 2017 to compliment the suite.
Datadog came to dominate the metrics-specific market because their product was so easy to use and reliable relative to every house-of-cards metrics pipelines companies were building in-house. Their lack of logging was notable though and that enabled both Sumo Logic and Elastic to thrive separately.
When Sumo Logic launched, they focused on logs and security insights. They did not have metrics and probably would have complimented Datadog pretty well circa 2013/2014. The real power of both companies was the ease of use and transparent scalability resulting in saving lifetimes worth of engineers time, and companies millions of dollars in operational costs.
Elastic had a slightly different approach. Elasticsearch was not initially built with logs in mind. Built on a full-text-search engine called Lucene, it was a natural destination to put logs which were nothing but unstructured text. They recognized this and found strong product market fit after bringing the developers and software behind Logstash and Kibana to create the well known "ELK stack".
The overall theme of this era would be that companies were producing way more data than previously, yet it was far less of a burden to buy one of these products off the cloud's metaphorical shelf.
These 5 companies experienced much success and are still in operation today as a result, and yet we're still not satisfied as consumers. Sure, these products are expensive, but they've proven time and time again that they result in major true efficiency gains for software development. Without them, a team is blind.
So if these products are our eyes and ears as engineers in operations, what does the future of logging, observability and security look like from a wholistic point of view?
The Future
Logging is here to stay.
As the most basic observability tool available for both operations and security, it also becomes the easiest to use and most flexible. A timestamp and a message makes for a very powerful abstraction; the continued popularity of syslog has proven that. Maybe it would be useful to have metadata in the form of tags or attributes, but logging standards aren't likely to evolve much farther beyond that.
Since logs aren't likely to change much in their form and structure anytime soon, what does the future of centralized logging hold? Why build something new at all?
Each era brings new technical hurdles and an order of magnitude more scale than the previous. At RunReveal we think we're on the precipice of the next era of logging, whatever that era is, because the core principles of simplicity, performance, and openness have been lost by the industry leaders. That's what Runreveal is focused on delivering first and foremost.