
Own your security data with RunReveal. Announcing Bring Your Own Database!
The problem with SIEM is closed source databases and data-hoarding. Take control of your security data.


Beginning today, RunReveal supports all existing RunReveal functionality with customer owned Clickhouse databases. We're providing this feature to customers at the enterprise tier, and we believe that customers should be able to retain full control of their data and still be able to leverage the full power of the RunReveal platform.
To understand why this is such an important release we need to talk about the types of problems that security practitioners have, and how we're helping our customers address them by achieving unmatched performance and cost-efficiency.
Charging rent for your data
The first problem we hear when talking to security practitioners is that SIEM is too darn expensive. One of the practices that has contributed to the high costs of SIEM is vendors who are collecting as much of their customer's data as possible but storing it in multiple layers of cloud storage vendors under the hood. This practice is hurting the security industry as a whole.
Cloud offerings in today's world have become so ubiquitous that your SIEM vendor is likely built on the same cloud providers your company uses. Your data becomes your vendor's moat once they control your data. Moving data out of a provider is nearly impossible once it's saved, and the vendors aren't incentivized to help you. The more you log the stickier the products become and the more likely that big increases on renewals are incoming.
RunReveal doesn't want to be in a situation where holding our customer's data hostage is our competitive advantage. We want our customers to be able to use the RunReveal platform and store their data with us, but know that if they want full control of their data it costs us less and we're still happy with that arrangement too.
Closed source databases
Another set of issues we hear about SIEM is deeply technical in nature. It's common to hear a grab bag of performance issues, operational issues, and interoperability issues that are caused by the closed source nature of many of the databases being leveraged in SIEM.
Datadog, Splunk, Snowflake, SumoLogic, Athena / BigQuery, are all closed source databases that security teams use. Closed source databases lead to a walled garden for all functionality like event management, visualizations / dashboarding, enrichment, access control, etc. You're out of luck if you're trying to extend the functionality of a closed source SIEM by yourself.
While closed source databases have been commercially successful over the past few decades, open-source online transactional processing (OLTP) databases like mysql and postgres became the default. Now, the open-source online analytical processing (OLAP) databases like Clickhouse are following suit. Clickhouse is used by Cloudflare, Microsoft, Disney, Twilio Segment, Bloomberg, and more for searching and indexing enormous datasets efficiently.
A SIEM built on Clickhouse gives security teams the ability to leverage an ecosystem of existing tools, prevent vendor lock-in, benefit from the contributions of over 1,000 people, and will perform as good or better than any proprietary datastore.
What to expect from bring your own datastore
For now, bring your own datastore isn't a feature that is in the UI. This will likely change at some point in the future, but a member of the RunReveal team will work with you on a call to record your cluster address and credentials.
Once we can connect to your cluster, the RunReveal table schemas will automatically be pushed to your cluster, and then all other RunReveal features will transparently use your clickhouse cluster as the underlying datastore.
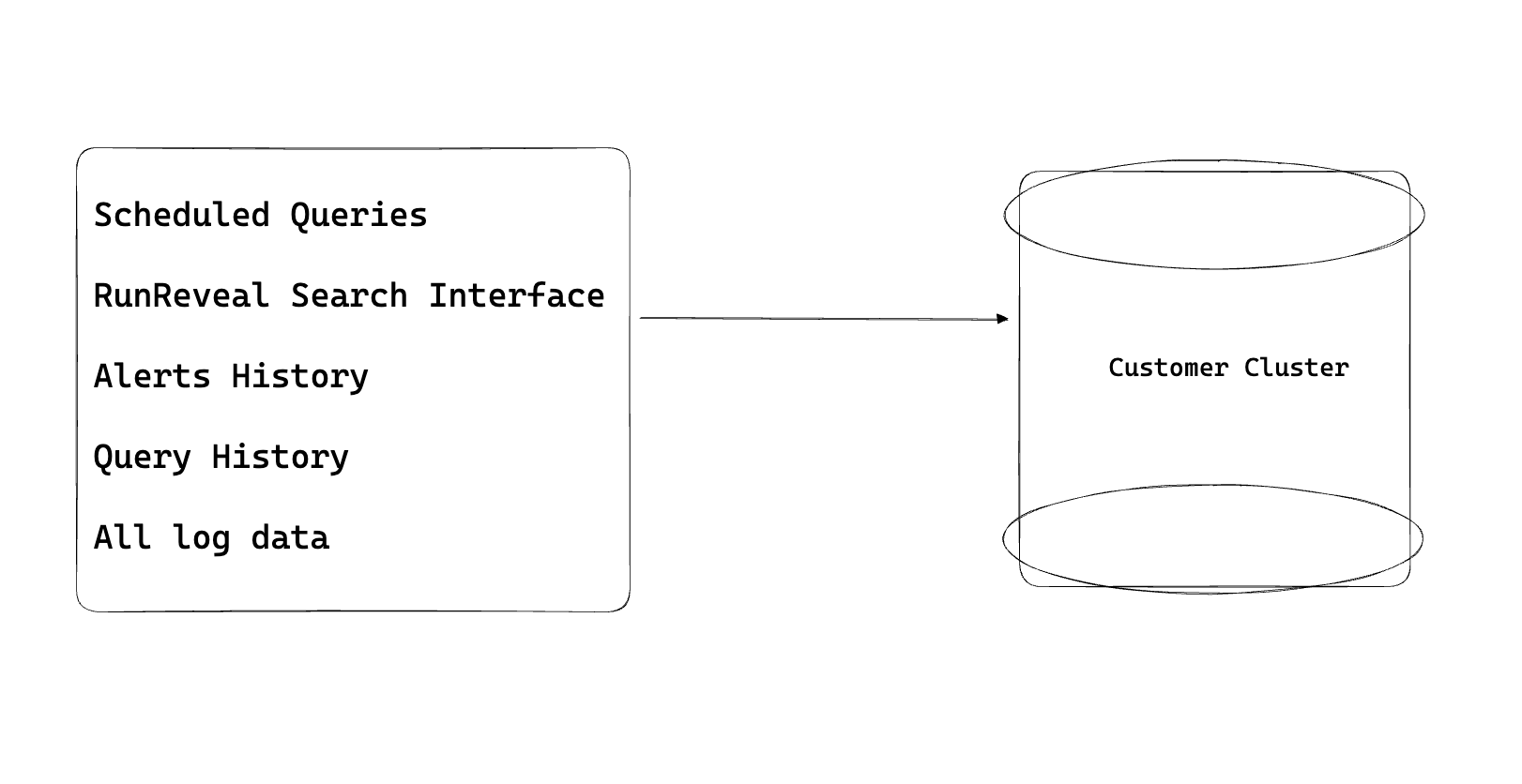
RunReveal will:
- Be courteous to your cluster, and ensure that when writing and reading we take care to not harm your cluster. More on this later.
- Ensure that the data we collect from your sources is reliably delivered to your cluster in a timely manner.
- Warn you when we may need to debug issues with your clusters.
- Alert you when we have issues writing to your clusters.
Our customers will:
- Need to ensure that the cluster is provisioned with adequate resources. We can help estimate this with you.
- Ensure that the cluster is up, reliably accessible, and reachable.
- Provide RunReveal with read and write access to the cluster.
Once set up, customers can use all RunReveal functionality with the database, can leverage open source tools that integrate with Clickhouse for visualizations, alerting, or any other purpose, and enjoy the benefits of faster queries!
Supporting customer datastores
Our goal was to make this product feel no different than using the standard RunReveal backend datastore. We added a new table destination_configs to our postgres database, where we store our customer's database connection information. We encrypt the sensitive fields using an AWS KMS key to ensure that unauthorized access to our database wouldn't expose our customer's clusters.
The control plane is simple to update, but next we needed to change our data-plane to begin writing to the new dedicated datastores.
There's a lot to account for when changing your architecture. "But what could go wrong?", I asked Alan, our CTO, when we started this. Luckily this isn't his first rodeo. The additional complexity starts to be obvious when looking at an architectural diagram.
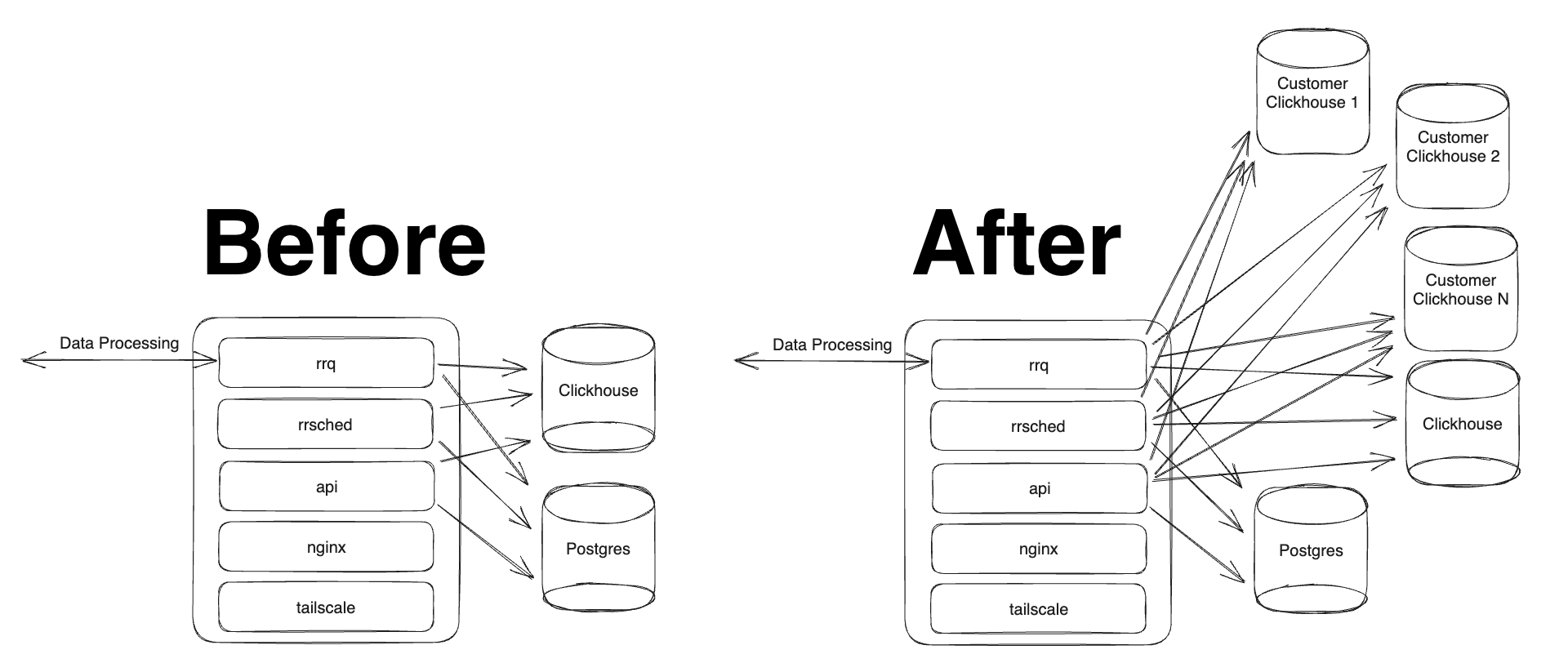
Batch Sizes. Clickhouse prefers to deal with large inserts of hundreds of thousands, or even millions of rows. When writing to a customer's on-prem database, lots of small writes could be complicated and harm the overall health of the cluster.
Our batch size decreases proportionally by the number of instance in our fleet because each instance runs the entire RunReveal stack. Generally this isn't a problem because our fleet size only increases with the number of customers and log volume, so insert size remains relatively stable.
Batch Size = (Sum of all logs) / Num Instances
But if each of our instances begins writing a single customer's logs to a single clickhouse cluster, it will likely cause our customer's datastores to get into an unhappy state.
Error Handling. When writing to databases we control, debugging issues is something we're fully empowered to do. If a write fails, we can access our cluster, search for the cause, and remediate issues. When writing to n customer databases, it should be assumed that clusters we write to will become unhealthy due to a variety of potential failures (i.e. the network, disk failures, power outages, natural disasters, overloaded clusters). We need to ensure our event pipeline can recognize and handle these issues so that operational issues don't cause permanent losses of our customer's data.
Schema Management. In our architecture, we have multiple components that rely on Clickhouse. We frequently run migrations on our database to create new tables, optimize indexes, create materialized views, manage roles and access policies, and other various operational tasks. These regular operational tasks will need to be automated.
Addressing the challenges
Schema management is a long-running issue that we have to manage. The primary issue to solve is error handling and batching. We determined that the simplest way to address both of these issues was to batch the data in object storage prior to the write.
The algorithm would look like this:
- If a customer has configured "bring your own datastore", stage the customer's data to object storage.
- Enqueue a message on a specific queue topic for that customer, to notify that the customer has data to write to their datastore.
- For each customer, at the same frequency and data quantities as our normal batching logic, read their customer's data and write it to their datastore.
- Once the data has successfully been written, delete the objects.
This design is simple, but it's very robust. Customers who have a datastore that goes down will keep their data staged in object storage until their datastore comes back online. It ensures that writes to the customer's database will be as large as possible, and since the data isn't stored long-term in object storage the additional costs are mostly bandwidth related.
A queue is necessary to ensure orderly consumption of messages. Simply listing a customer's objects and writing them to the destination datastore would lead to duplicated data, or would require complicated database locks and scheduling that we didn't want to implement.
What's next?
RunReveal's goal is to help our customer's take back ownership of their security data, and enable them to not need to make the sacrifices they're currently making with the existing set of incumbent vendors.
With this change, RunReveal can scale from customers handling a few kilobytes per month, to a few hundred Tb per month. Customers can own their own data, and not need to worry about each middle layer extracting a healthy margin and charging rent.
If you're interested in trying RunReveal or getting email updates, then fill out your email below. RunReveal is hiring a product engineer in the United States to help us build the future of security data, so email us your resume today!