
Kawa: The Event Processor for the Grug Brained Developer


Today we're releasing an open-source project called Kawa, an event processor so simple and easy to use that even grug brained developers like us can grok it.
Kawa is a labour of love borne from Go design principles, and strives to achieve the elusive trifecta of simplicity, performance, and reliability. We believe it's possible to build a simple, easy to use framework without sacrificing reliability or performance. Kawa is the event processor powering our event pipeline at RunReveal and enables us to scale to thousands of events per second, per core.
Something as conceptually simple as log processing should also be simple in practice. We're not going to make any wild claims to support every imaginable use case, but we do want to make it easy for you to take logs from wherever they are and get them to wherever they can be more useful. We also want it to be easy to implement new sources and destinations if one doesn't exist yet for your favorite software. One goal of ours is to enable developers build sources and destinations in just a couple of hours, presuming they're familiar with the patterns used in Kawa.
In this post we'll explore the problems and motivation for this software as well as dig into the design and implementation of the framework.

The Problem
Why is it still so hard to do distributed log processing? That's a question we kept asking ourselves when it came time to build a new logging, metrics and event pipeline at RunReveal. This is something we've done a few times in our careers and it hasn't gotten any easier! There are dozens if not hundreds of options available, but every one we've encountered comes with pretty major tradeoffs.
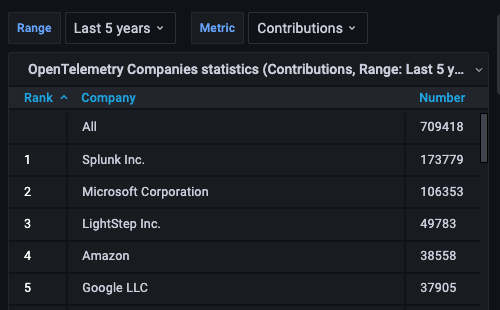
On one end of the spectrum, we have tools aimed more at the specific use cases of collecting telemetry. These often require high volume, low overhead processing and aren't quite as concerned about exactly once processing, as long as the data gets to where it needs to be. Despite coming from a more pragmatic angle, they still miss the mark on ease of use. Vector is a popular flexible telemetry daemon, but extending it requires knowledge of Rust and the process to build plugins or extend the software is poorly documented. OpenTelemetry is a project that aims to standardize all telemetry collection, but by trying to please everyone and make something idiomatic for all languages the result is a bit of a hot mess. The interface used for log collection in the opentelemetry collector makes grug's head spin. Looking at the contribution statistics we can't say we're terribly surprised.
On the other end of the spectrum, we've got flexible, more generalized stream processing frameworks inspired by Google's Millwheel. Frameworks like Dataflow, Apache Beam, Apache Flink, Spark Streaming aim to be highly consistent and flexible, but the complexity skyrockets as a result. These frameworks allow you to build execution flows which are deep directed acyclic graphs and are suitable for highly scalable workflows that can do very advanced calculations across massive datasets. We like the type flexibility, but the frameworks are unsuitable for focused workloads like running a lean log collector daemon.
At RunReveal we wanted something simple enough that could be deployed in a single binary that we could iterate on quickly, process arbitrary data types, and still maintain a high level of efficiency and performance. We wanted a framework which would fit just as well in a tiny daemon running on IoT devices as it would running in a large cluster doing analytics workloads. The existing tools at our disposal that we discussed above are great if you're sticking to the paved road for which they were built, and they all reflect a great lesson in engineering: define the problem you're looking to solve and solve it well. We're taking lessons from these frameworks and using them to inform our future development for our opinionated use case.
Designing for Simplicity
The concepts underpinning Kawa can be understood in one-sitting.
Sources are where the events comes from. Destinations are where the events are headed. And Handlers process the events.
We need to be able to handle errors or failures gracefully, process events with at-least-once delivery semantics, and scale to thousands of events per second per core while remaining efficient.
With those requirements, we came up with the Source, Destination and Handler abstractions. They are perhaps best understood by looking at the core handler loop in processor.go, found at the root of the repository, along with their interface definitions.
// processor.go
func (p *Processor[T1, T2]) handle(ctx context.Context) error {
for {
msg, ack, err := p.src.Recv(ctx)
if err != nil {
return fmt.Errorf("source: %w", err)
}
msgs, err := p.handler.Handle(ctx, msg)
if err != nil {
return fmt.Errorf("handle: %w", err)
}
err = p.dst.Send(ctx, ack, msgs...)
if err != nil {
return fmt.Errorf("destination: %w", err)
}
}
}
// types.go
type Source[T any] interface {
Recv(context.Context) (Message[T], func(), error)
}
type Destination[T any] interface {
Send(context.Context, func(), ...Message[T]) error
}
type Handler[T1, T2 any] interface {
Handle(context.Context, Message[T1]) ([]Message[T2], error)
}
This loop encapsulates the essence of the framework. Some things of note that we'll dig deeper into in the following sections:
- Each stage is a blocking call, which must be cancellable by the passed-in context.
- Each iteration of the loop handles one event at a time from a source.
- An error returned from any stage at this level is fatal.
- Handlers aren't allowed to acknowledge event processing success or failure.
Blocking APIs
Maintaining and debugging concurrent code becomes complicated quick. That's why we made the conscious decision to make every call crossing an API boundary appear synchronous. What could be a mess of channels, asynchronous functions or callbacks, now becomes readable in a very imperative style.
Note that this doesn't mean that each call is blocking the processor or prevent any of the stages from doing their own concurrent work behind the interface. Sources and destinations will often have to do so, to handle fetching and reading in new events while waiting for other events to be processed by the handler, and sent to their destinations.
One Thing at a Time
A crucial decision in developing this framework was to handle one event at a time. This approach simplifies interfaces for sources and destinations, assures better delivery, fine-tunes flexibility in parameters, and cleans up error handling.
Sounds limiting? Imagine handling multiple events in a batch. Now, consider the intricacies of acknowledging the success or failure of processing those messages. This is where the principle of "one piece flow," a quality control strategy adopted by lean manufacturing, comes into play.
In the context of our event processing, an analogous principle helps handle issues that arise from errors or exceptions processing any arbitrary set of events. We handle these issues individually, not in batches. This approach ensures better-informed decisions, especially when temporary network or system errors make forward progress momentarily unavailable.
Don’t just check errors, handle them gracefully
This is taken straight from a Go proverb. Every error in the core loop is currently considered a fatal error and returned to the caller. We do this because we believe errors should be handled as close to the source of that error as possible, since the closer you are to where it occurs, the more context you're likely to have to be able to successfully handle it.
Furthermore, every source, destination and handler is going to have different ideas about what errors can be retried or ignored. Therefore, we leave the responsibility of error handling to the Sources, Destinations and Handlers. There may be developments in this area as it relates to some stream processing systems ability to handle negative acks, but we're not taking on that work today.
Handlers are just functions
Perhaps most notably in all of this, a handler is just a function which accepts an event, and returns zero or more events, but does not have the ability to acknowledge the event was processed.
One or more events returned without an error, then the source event was successfully processed. An empty slice and no error, the source event was successfully processed and no events need to be sent to destinations. Any error returned is fatal, regardless of the state of the returned slice.
We don't pass the ack function into the handler because it would create two possible places for it to be called: from handlers and from destinations. If we want to guarantee delivery to a destination, then any code calling ack inside the handler would break that contract.
Because of these properties, handlers are by default idempotent. They take the complexity out of writing the handlers which are actually doing work and implementing the business logic. Handlers are where custom stream-processors can be added to modify, alert, multiplex, or suppress logs. Much of the core logic at RunReveal is implemented in handlers including the WebAssembly for alerting and transformations.
Scalability
So if everything is blocking, and events are processed one at a time, how on earth is it possible to scale this system?
First off, we're not trying to be the fastest event processor out there. That's a fools errand best left for the high frequency traders and performance junkies. We do have a requirement to process thousands of events per second per core, ideally in the 10k-100k range.
To achieve that goal, we lean into Go's strengths in concurrency and parallelism.
First, Sources and Destinations need to be safe for concurrent use, which may be a challenge for those first getting started with Go, but those are also the most reusable components so should only have to be built once.
Then, so long as the handlers being used are idempotent, we can trivially parallelize the processor, meaning we can scale to however many or few go routines as we'd like to control throughput and resource usage. Pretty neat, huh?
Separating the concurrency of Sources, Handlers and Destinations is directly inspired by Rob Pike's "Concurrency is not Parallelism" talk, which is to this day our favorite presentation on the topic of concurrent designs.
Reliability
Message delivery guarantees for any system depends on many factors. The most important of which is the guarantees provided by the systems any given software interacts with. A system can only provide as much assurance as the systems that it integrates with.
As such, delivery guarantees may vary depending on the source or destination being used in question. If there's no write guarantees for the destination, or if your source cannot effectively track the delivery status of messages, then delivery guarantees are going to be weak, if present at all.
Recognizing that the guarantees are dependent on the integrations, we've implemented a simple and flexible system for destinations to communicate back to the sources the delivery status of any given message via acknowledgement callbacks.
Every source implemented in Kawa gets to define it's own callback for acknowledging whether or not a message was successfully processed. Destination plugins must call this callback function if and only if the message was successfully committed to the destination. This property gives us at-least-once processing.
Kawa at RunReveal
Although Kawa is still in its early stages, it has already proven to be instrumental in production at RunReveal by enabling us to build sources and destinations quickly. We hope that you'll get similar value out of the framework.
You can use it today! If this framework looks compelling to you as a library then now is the time to get involved and give us your feedback. We want it to be broadly useful beyond just log processing or telemetry applications while still keeping it simple.
If you're interested in just the daemon, you can use that today too! See the documentation for how to configure it to send nginx logs to RunReveal or another destination of your choosing like S3.
We've got a lot of polish that still needs to be done (more docs, dedicated docs site, testing, modularization), but it's unlikely that the core principles or interfaces will change much before reaching v1.0.