
Introducing RunReveal Blob Destinations Beta. Your security logs when you need them.


Today, we're excited to release blob storage destinations to all pro and enterprise tier RunReveal customers. Our customers can now easily collect logs from different log sources, use those logs for detection and threat hunting purposes, and stream those logs to low cost blob storage for long-term retention.
Most security teams end up struggling with death by a thousand cuts of data problems. Integrating with cloud providers, juggling different log formats, and short retention periods in cloud services. Even worse is handling these problems during an incident when the pressure is high and fiddling with JSON leads to hours of lost time.
RunReveal is helping our customers solve these problem with Blob Destinations. Today, s3 is the standard place to store almost anything. We already supported custom ClickHouse clusters as a destination but starting today we'll collect your security data, normalize it, and write the normalized format (along with the original format) to blob storage.
We see two main use cases for Blob Destinations. First, when an incident happens we want to make sure you can rely on RunReveal and aren't bogged down with data problems. Once we collect logs in S3, you'll be able to use RunReveal to re-ingest years old data seamlessly. Second, s3 is the de-facto storage solution for all kinds of workloads, and security teams who are building their own detection tools can easily use RunReveal as part of their stack.
There's no magic in data-engineering though. Let's look at how we built this product.
Normalize, collect, enrich, and store all of your logs
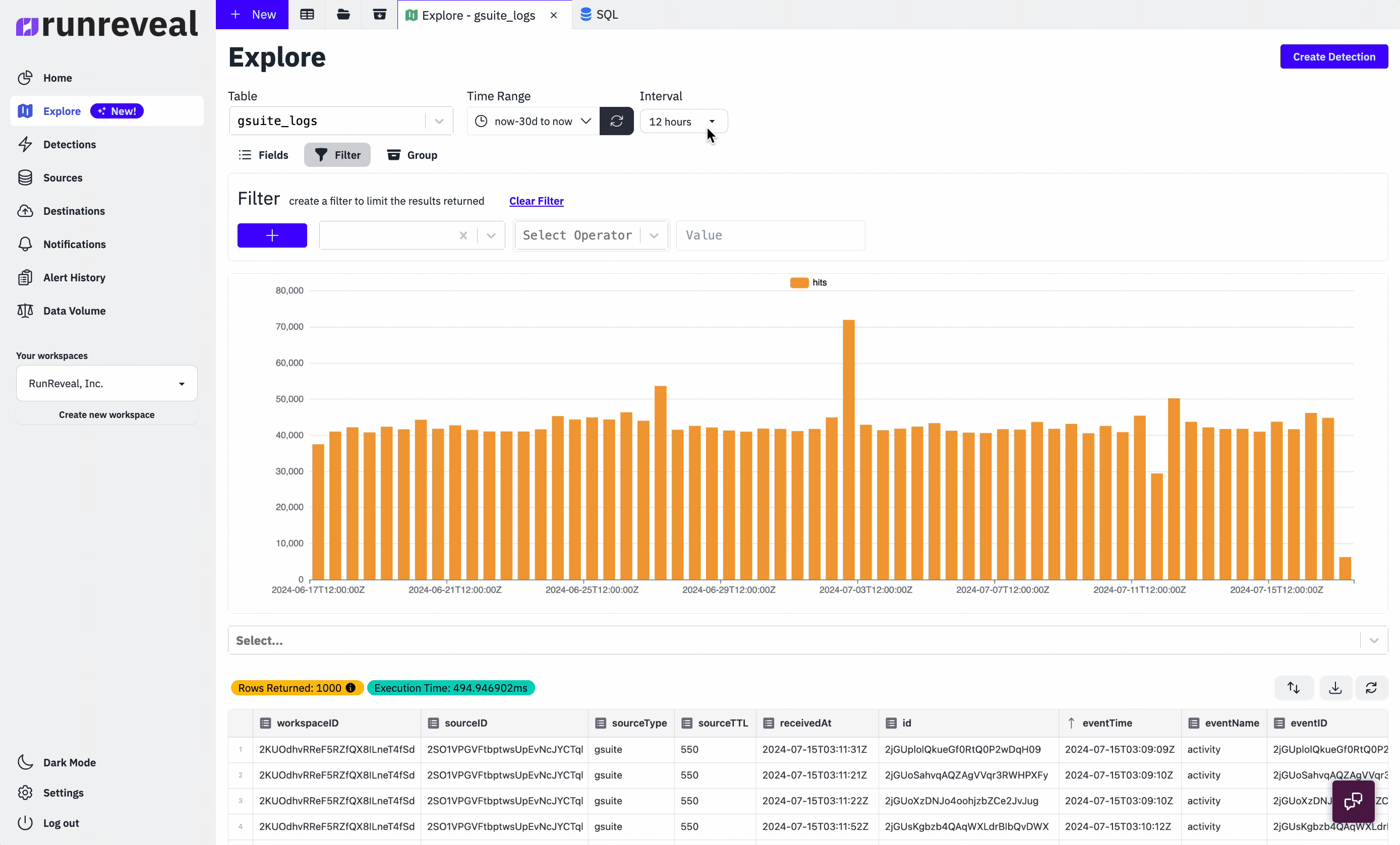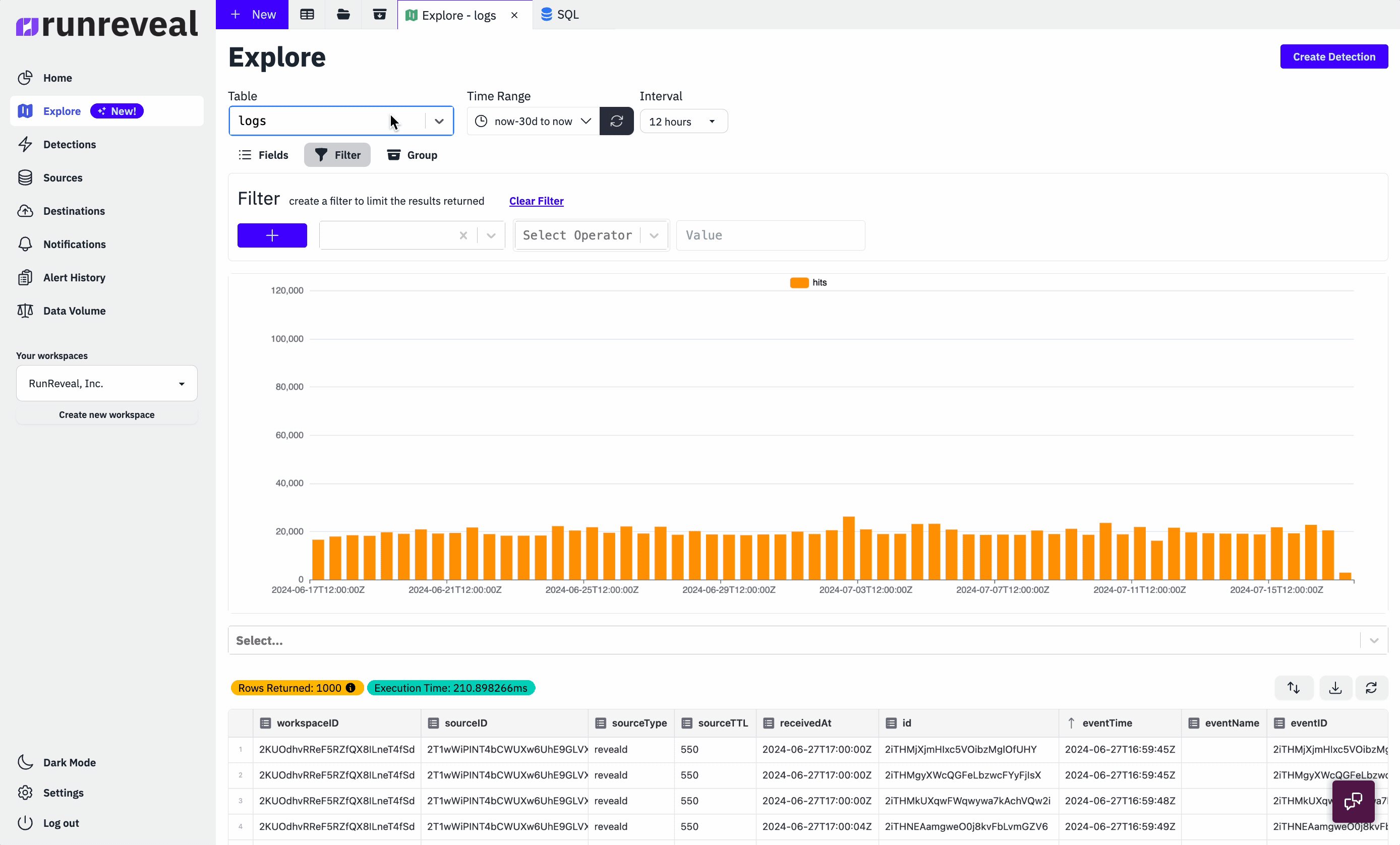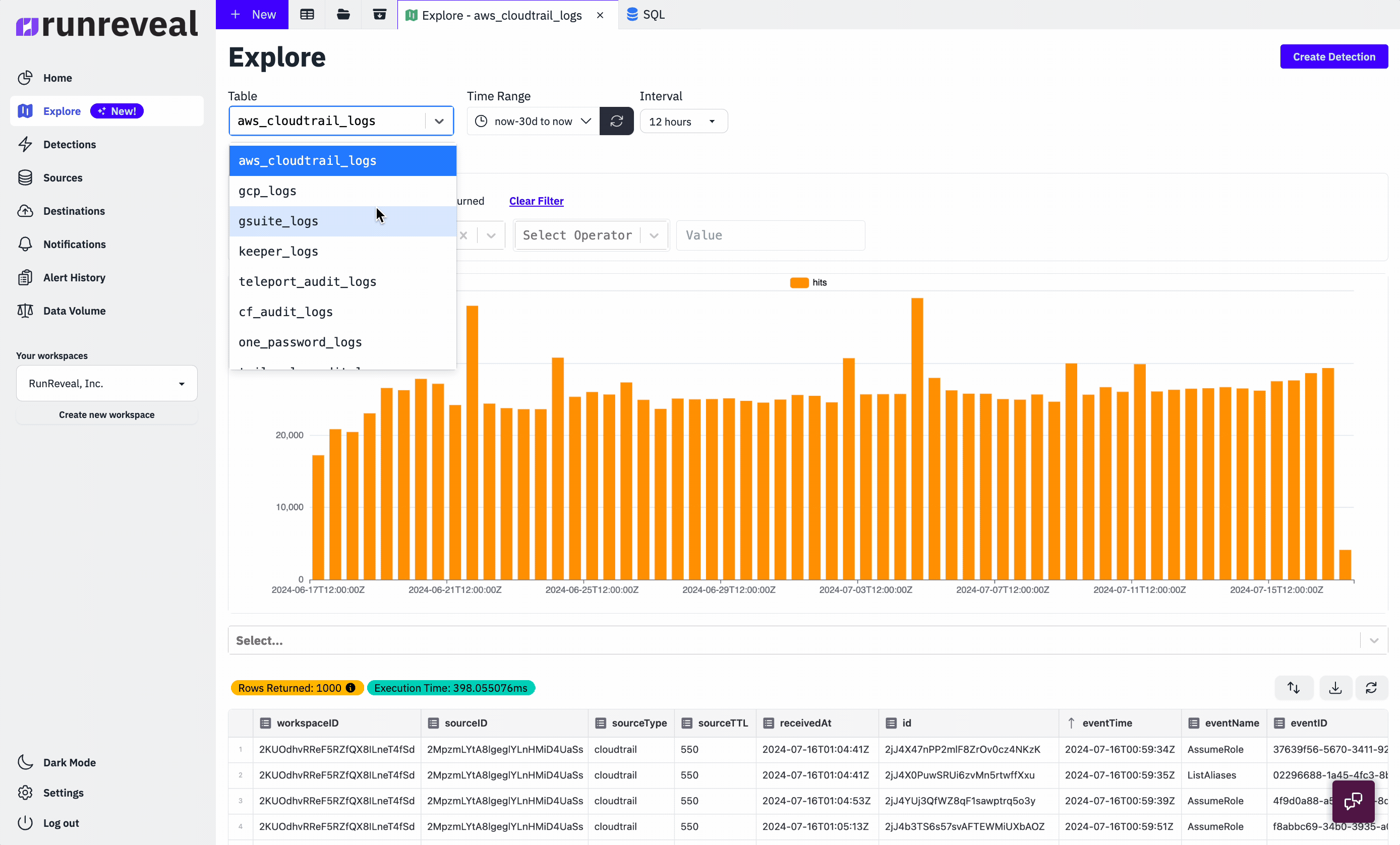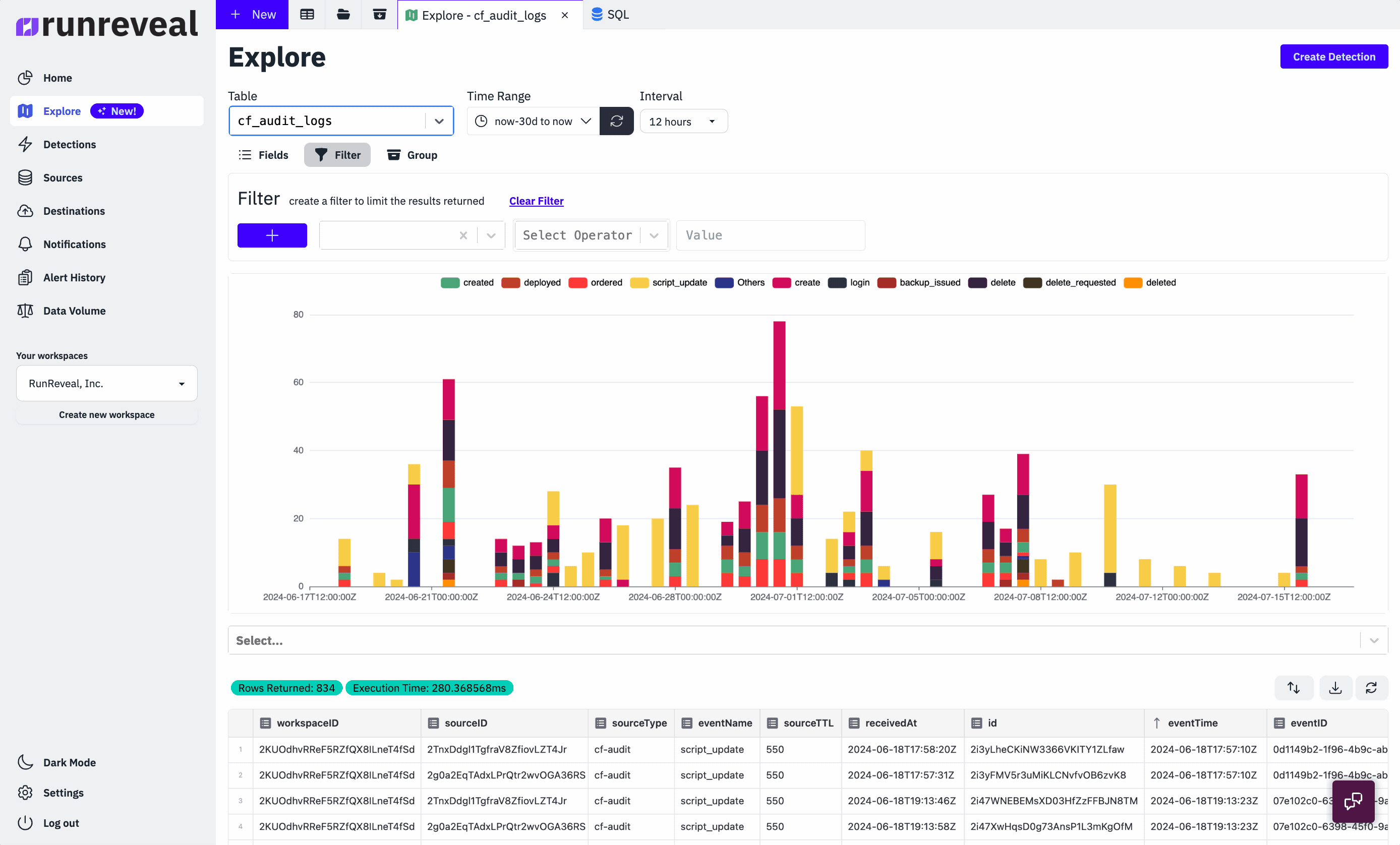
RunReveal integrates with dozens of security, cloud, and on-prem log sources. These integrations work in a variety of different ways but the goal of each source is the same.
- Integrate closely to the log provider, RunReveal should make it as easy as possible to collect the logs.
- Normalize each individual log into a unified format.
- Ensure that each log makes it to it's destination successfully.
Every type of log we receive is re-reformatted into a unified schema that RunReveal invented. Our data pipeline looks something like this.

Once RunReveal collects, re-formats, and enriches the logs into a unified schema, we store the resulting log into one (or more) ClickHouse clusters. For many of our customers, these ClickHouse clusters exist on-prem or are managed in the cloud. It's important to note that part of the unified format is actually the raw json log that we initially collected!
Storing the raw log is important because oftentimes logs don't fit neatly into any unified format and security analysts want to interact with the logs in a format they are familiar with. We apply a variety of views and materialized views, that interact with the raw log and unified schema alike. This allows our customers to see logs in their original format, custom formats like the OCSF, or any format they want. The raw logs and unified schema work together to make an incredibly fast and user-friendly threat-hunting experience at any scale.
Long term storage with blob storage
We wanted to modify our data-pipeline to stream logs to a bucket. Customers who are doing their own custom data-processing or want ultra long-term storage can then either use those logs themselves or the RunReveal platform could help customers use those logs.
After processing each log we implemented a batcher (instead of, or in addition to ClickHouse) that will write the logs to blob storage. This batcher currently supports per-hour partitioning of data by directory, but we plan to enhance this so the data can further be partitioned by log type.
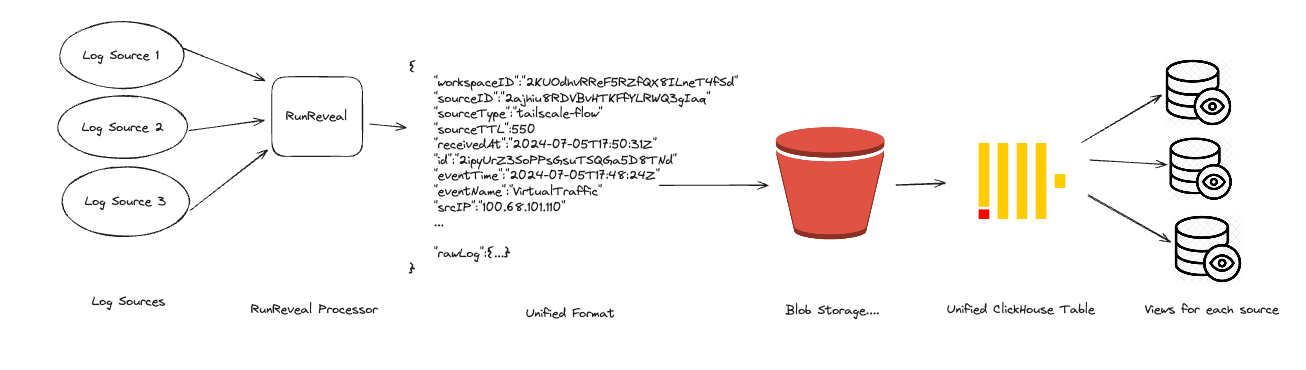
Once the logs are stored in a bucket, after being formatted into the RunReveal unified format, these logs can simply be read and re-ingested into a datastore at a later date with little to no processing. Re-ingested logs are treated no differently from other logs, and can be used for threat-hunting, detection, or read from integrations like Jupyter Notebooks or Grafana.
Getting Started with Destinations
To get started with destinations, you just need to provide us with a bucket name, bucket region, and IAM role that we can assume. Once these details are provided, we'll begin batching and writing your logs to the s3 bucket immediately.

The logs are written to s3 in json line-delimited format in batches, and the batching process happens transparently in RunReveal's pipeline.
A number of features are planned for destinations in the near future to truly make this an enterprise product.
- Configurable batch sizes, appropriate for extremely high volume and low-volume sources.
- Support for any kind of S3 compatible destination. Currently it's just s3, but GCP, Azure, and Cloudflare's R2 are planned.
- Support for re-ingestion. RunReveal supports "backfills" in our product from a bucket already if you have an existing bucket filled with your logs, but re-ingesting ranges of logs by date and sourceType is critical for IR purposes.
You can expect many of these features and the general availability of this product to be released before the end of 2024.
What's next at RunReveal
RunReveal already supported ClickHouse destinations for enterprise customers, but S3 compatible blob storage has become the low-cost catch all solution for many security teams. We plan to continue to improve this feature over the coming months but we wanted to launch and save time for security teams working on centralizing their logs into a single bucket.
This announcement, along with another we have planned just before DEFCON and BlackHat next month, work together to create a new architecture for detection. We're excited to offer destinations to our customers and look forward to our next announcement that will knock your socks off.
Reach out and let us know if you'd like to meet at DEFCON or BlackHat this year. The RunReveal team will be attending a hosting several events, and we look forward to connecting with our customers in person.