
Introducing RunReveal Pipelines Beta
Announcing Pipelines to build custom data pipelines to route, filter, match, detect, transform, and enrich security logs for better threat detection and insights directly in the RunReveal platform.

Today RunReveal is announcing our Pipelines product. All customers can use Pipelines in beta to build their own custom data processing pipelines that filter, match, detect, transform, and enrich their logs in any order or complexity.
The secret to detection is having clean data, and by the time your logs reach whatever storage system you're using, the data is as clean as it will ever be. Becoming a world-class detection and response organization means you're as worried about the data going into your detection and response process as you are worried about the alerts coming out.
Throughout 2024 RunReveal expanded our pipeline's functionality because we knew our customer's needed core components like filtering, enrichment, etc, but we kept hearing about use cases that didn't quite fit in our exact pipeline.
- "I wish you could filter by a specific field name after transforming the data. I want to filter all logs from GCP except from this one specific container."
- "I wish I could keep my flow logs just for egress from my VPC, and get rid of all of the internal junk."
- "Can I handle all of my WAF logs differently? I want to use them for detection but throw them away otherwise."
Now all of that is possible and our customers can build any security data pipeline they need. Over the coming weeks we'll highlight some specific use cases and deep dive into how the product works.
A pipelines example with network logs
Flow logs are a real issue for most security teams because the volume can be enormous and costly. But network logs can also be very valuable when you see network connections to unexpected places.
The default RunReveal processing pipeline will transform, enrich, filter, detect, and then finally store all of your logs. It's also worth noting that we store all logs that match a detection as a finding, regardless of filtering.
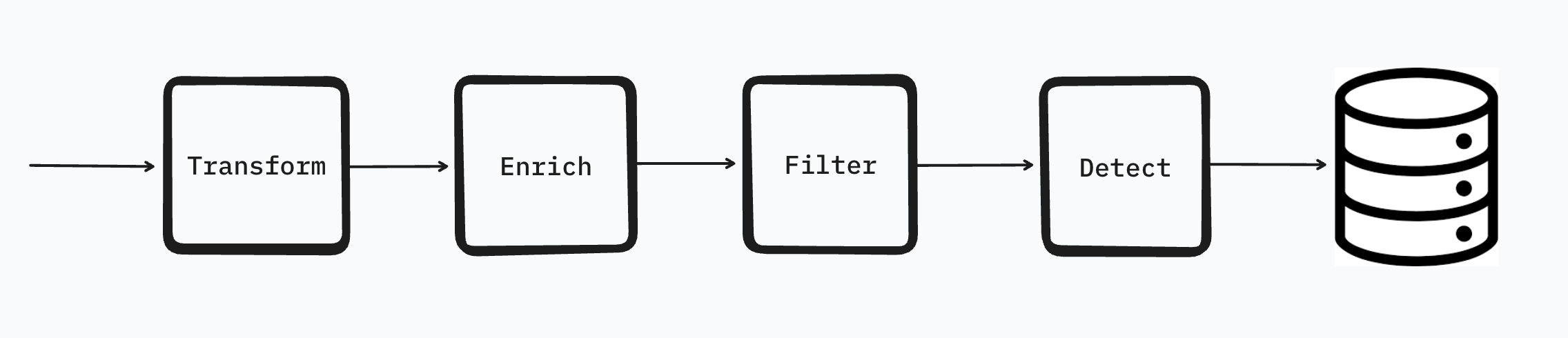
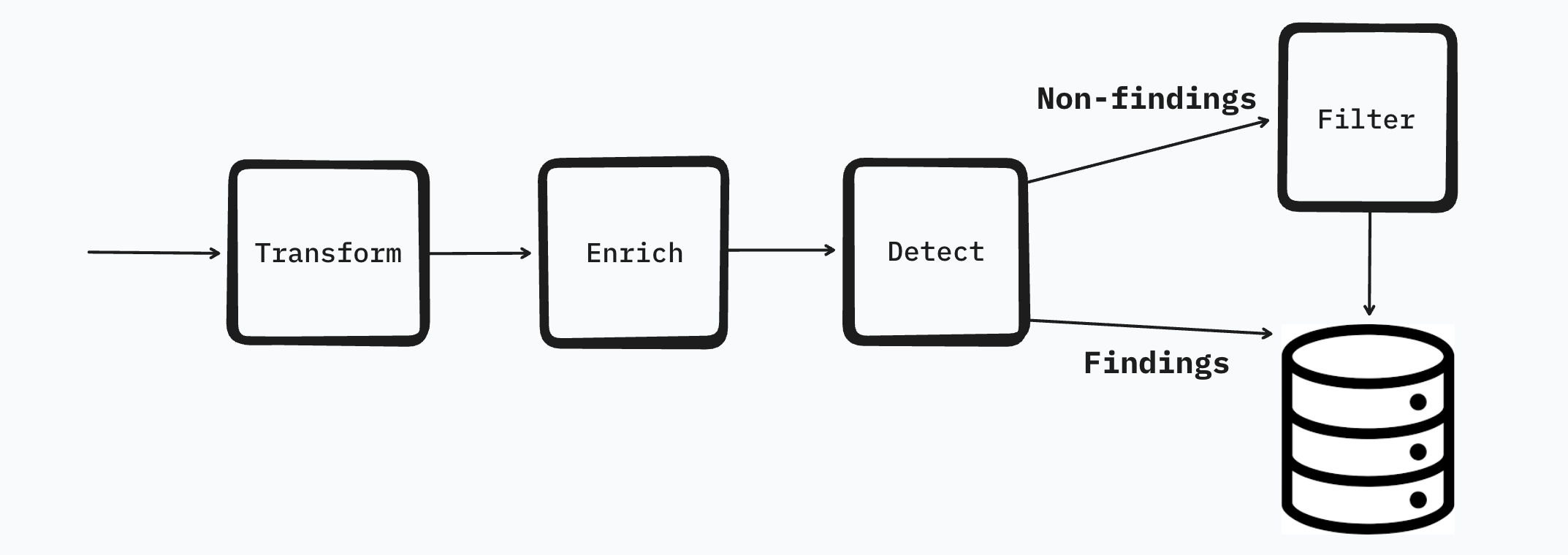
In most cases this ordering is great but when it comes to network logs this ordering is a little problematic. Just by looking at the subnet or autonomous system name it's nearly impossible to tell if a network log is worth keeping. A subtle but major change would be to swap the detection and filtering step so that:
- We can scan all of the logs for things like tor exit nodes, known malicious IPs, and other detection scenarios.
- We can filter the traffic to a more manageable quantity so it's still useful but without all the noise. In this example I set up a filter where the flow logs for class B private ranges are filtered.
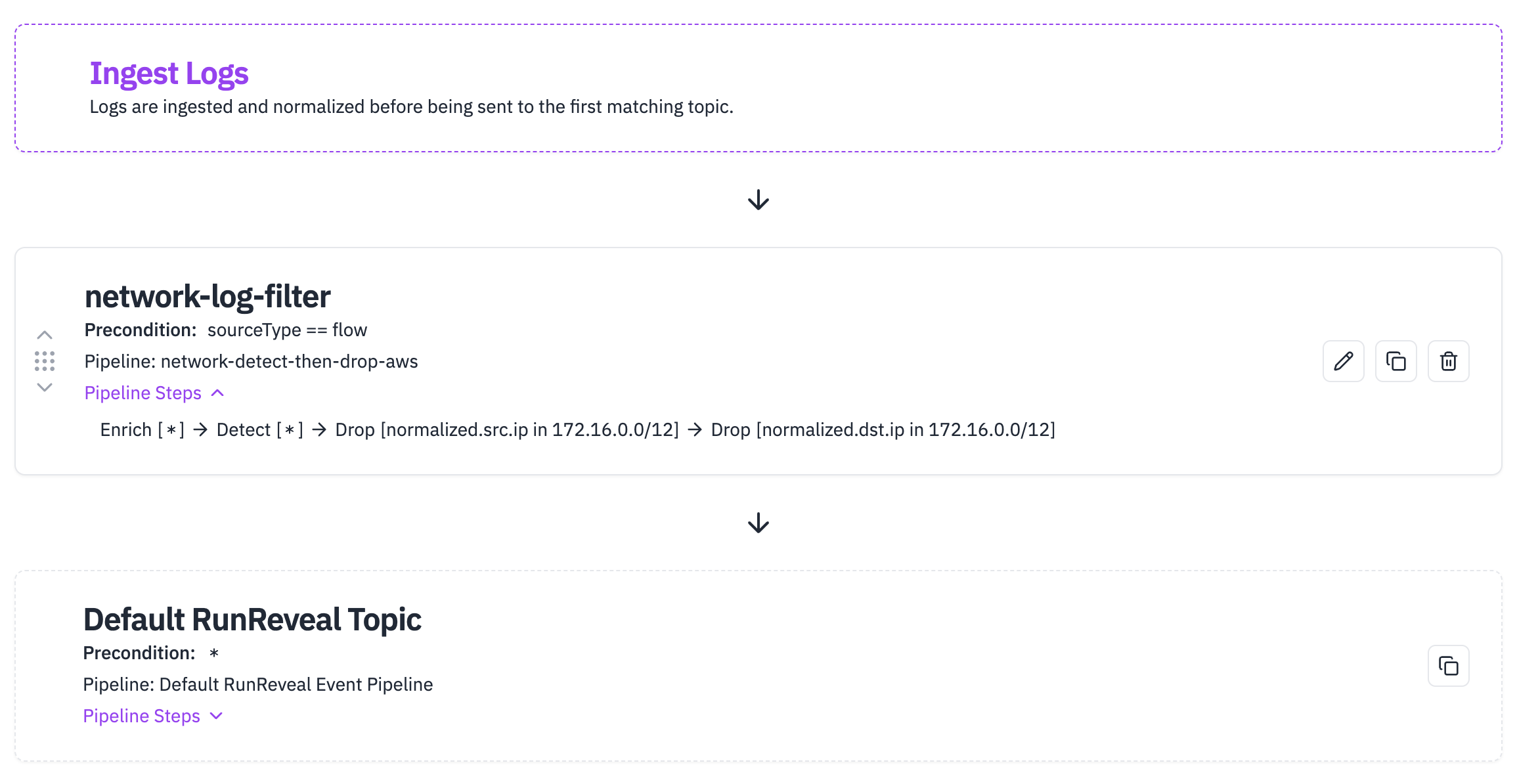
The new data pipeline would look something more like this.
To make this kind of pipeline we configured our enrichments, detections that we wanted to run, and then decided to drop all logs where the srcIP or dstIP is in the CIDR 172.166.0.0/12. We are able to build this out quickly by drag and dropping the few steps we have into the order we want.
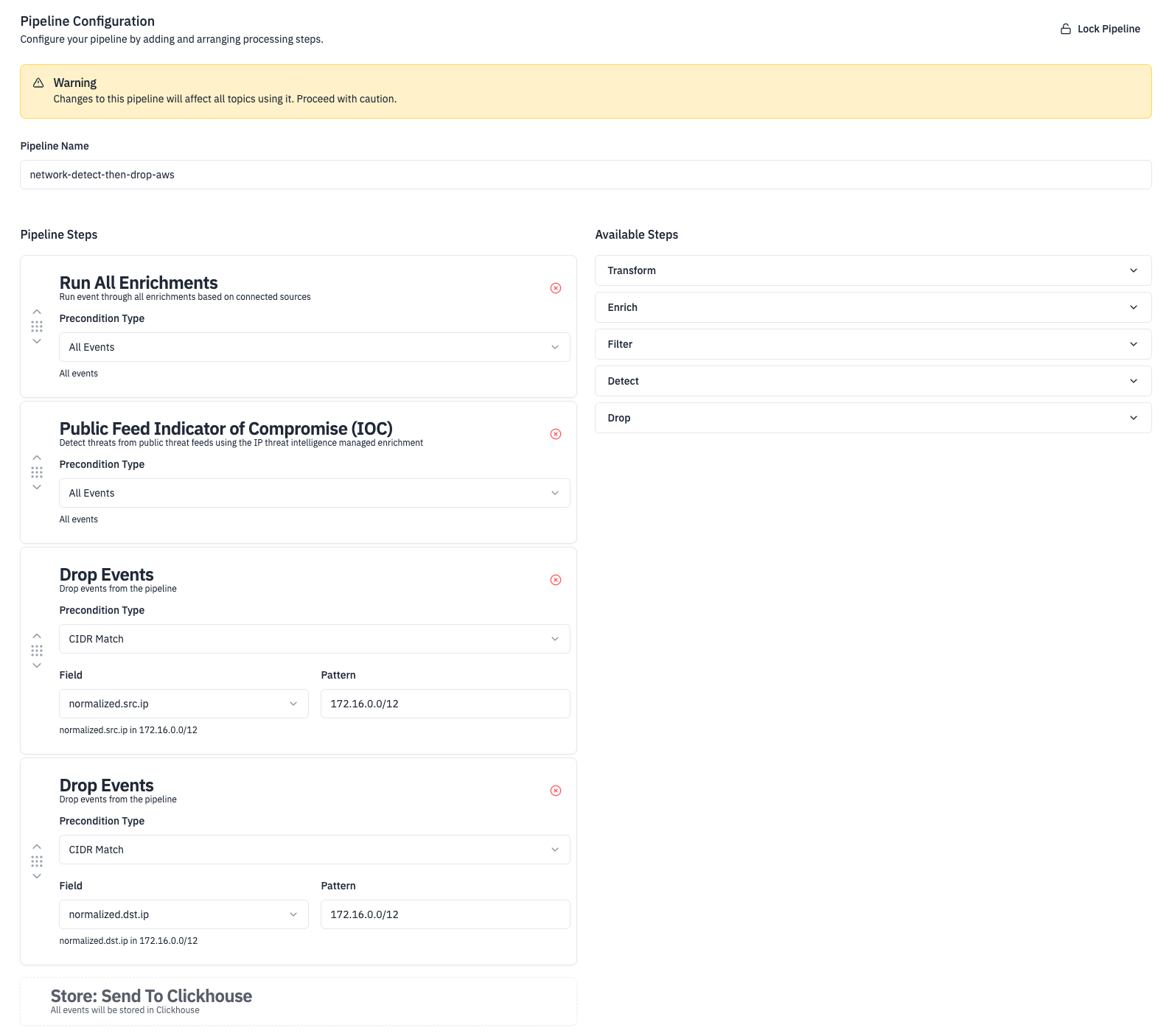
Once we finish the configuration we then need to configure the conditions under which data is sent down the pipeline. In RunReveal we call these "topics." You can set a topic based on any attribute of the log like where the log came from, the IP / CIDR, even whether or not it matches a specific regex.
In this case, we just need to check if the log is an AWS Flow log and then we'll invoke the pipeline we just created. You'll also notice that just like pipelines, ordering matters in topics.
Once we set this up our flow logs are immediately processed using this new pipeline. Our log network volume dropped according to our expectations and we were left with only the flow logs where we were calling out to external IPs, or external IPs were communicating with our public IPs. This ended up being a much more manageable quantity of logs and decreased our flow log volume from ~41MB per hour to ~4.8MB per hour.
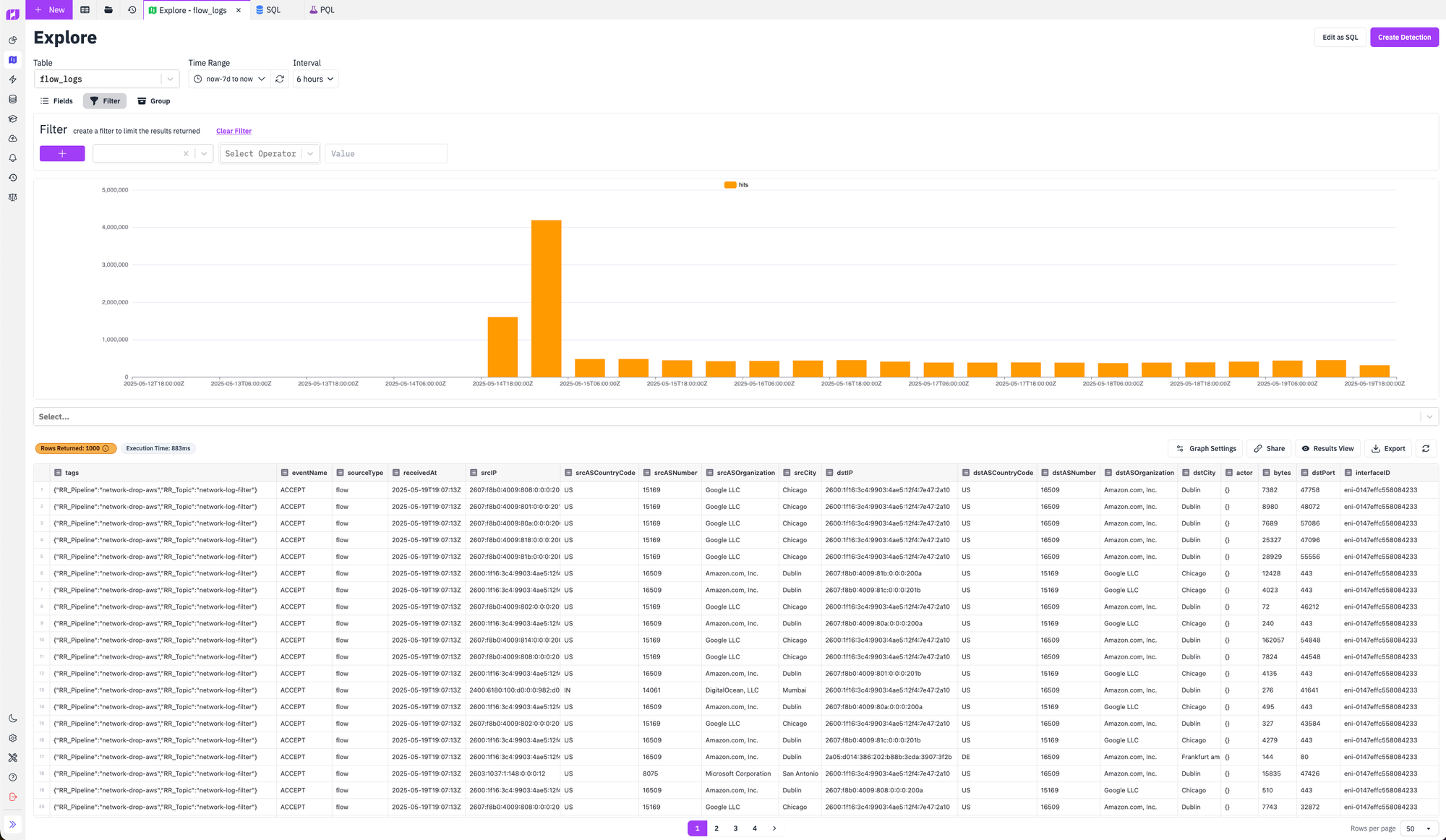
Finally, notice above that the pipeline and topic that processed the logs is stored in the tags column. This allows you to search your logs based on how it was processed and provides visibility into exactly what's happening with each individual log in case things are ever processed differently than you expected. Neat!
What's coming next
Pipelines are an extremely useful feature that every security team needs once they get past a trivial amount of scale. We plan to continue working on it in preparation for a GA release! For use like the one above it's phenomenal, but we're still working on more "destination" oriented use cases like multi-writing a log or choosing hot-cold destinations from within the pipeline. We also plan to integrate these features with our detection as code capabilities so you can have "pipelines-as-code" and manage your pipelines within git.
Every security team should have the control over their data so that they aren't stuck choosing between blowing up their budget for the year or completely overlooking their network logs. Not every log is the same and so it's logical that you might have quite a few different ways that you want your logs processed, enriched, filtered, etc. and it's our job to facilitate that.
RunReveal is hiring engineers who are excited to disrupt the two decade old SIEM category. Check out our careers page and reach out to learn more about our plans!