
CVE-2024-22412 - Behind the bug, a classic caching problem in the ClickHouse query cache

In December we reported a Bypass of Role Based Authentication in ClickHouse's open source product, versions v23.1 and earlier. We worked with ClickHouse to report and disclose the bug, and the issue was disclosed March 18th as CVE-2024-22412.
This bug is a classic product security problem. All the code was working properly but two features, when used together, had unintended security-compromising consequences.
You can read the entire security advisory on GitHub, including a PoC, but let's dig into the issue to fully understand the bug and how it was fixed. To get started you'll need to know about the underlying features of ClickHouse that weren't working together properly.
Role Based Access Control
The idea behind role based access control in ClickHouse is not unique. Roles are logical entities that can be assumed by users and are assigned a set of policies. Support for roles was added to ClickHouse in 2020, and the primary use case for roles is restricting what data can be accessed, and what types of actions can be taken on that data.
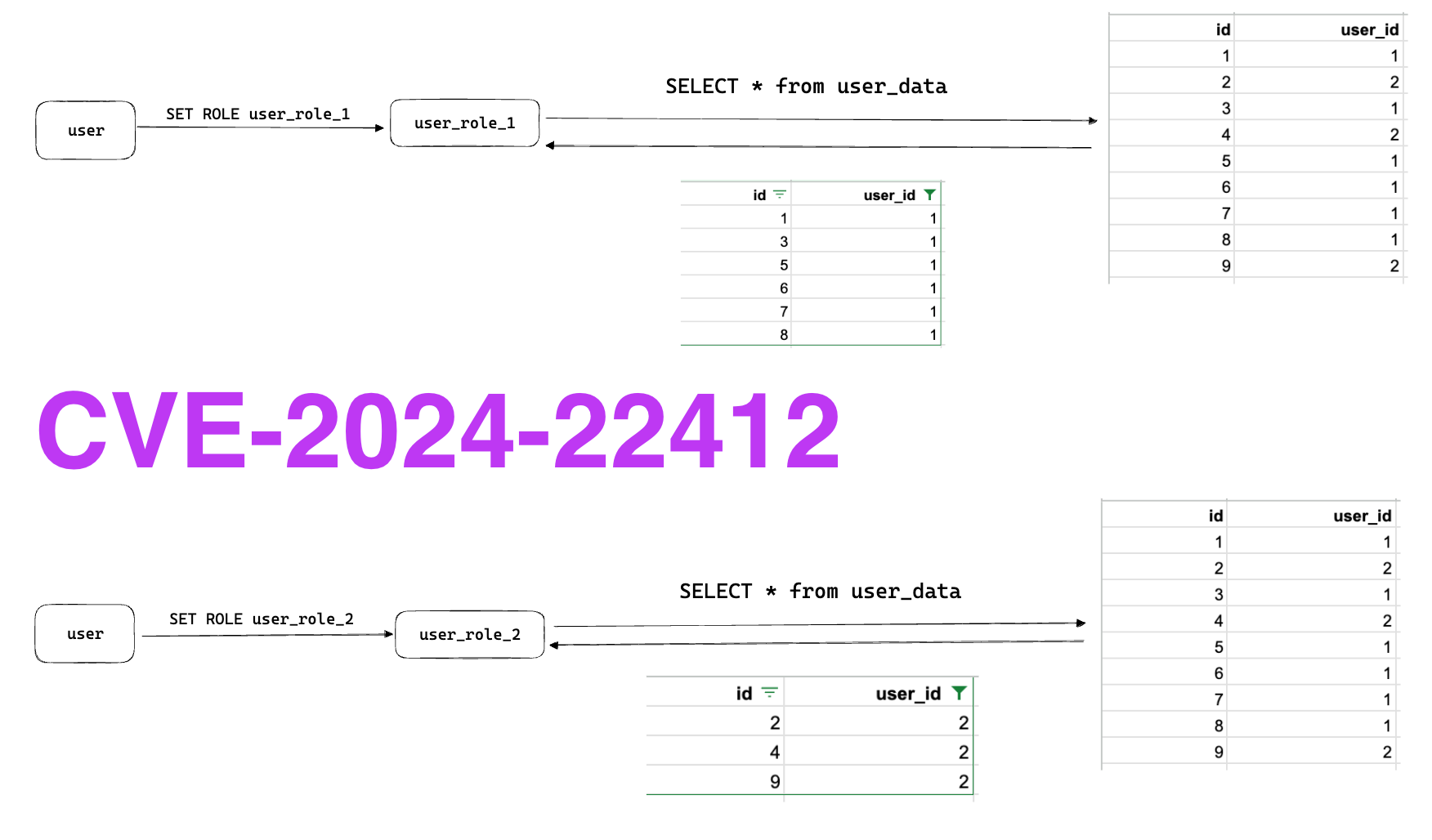
Let's looks at a toy example from our PoC. Assume we want to create a table and roles to separate data between different users. Using roles, we could create a role for each user, and rely on the user_id column to separate those roles.
CREATE USER user IDENTIFIED BY 'R~zo3PsI0RPhx';
CREATE TABLE user_data
(
id UInt32,
user_id UInt32
)
ENGINE = MergeTree
ORDER BY userID;
CREATE ROLE user_role_1;
GRANT SELECT ON user_data TO user_role_1;
CREATE ROW POLICY user_policy_1 ON user_data
FOR SELECT USING user_id = 1 TO user_role_1;
CREATE ROLE user_role_2;
GRANT SELECT ON user_data TO user_role_2;
CREATE ROW POLICY user_policy_2 ON user_data
FOR SELECT USING user_id = 2 TO user_role_2;
GRANT user_role_1, user_role_2 TO user;
INSERT INTO user_data (id, user_id) VALUES
(1, 1), (2, 2), (3, 1), (4, 2), (5, 1), (6, 1), (7, 1), (8, 1), (9, 2);
Once setting this up, the policies for user_role_1 or user_role_2 will allow each role to query the user_data table and only see the data with the corresponding user_id from their row policy.
Here's what the difference looks like in practice, and this architecture is more or less how RunReveal manages our customer's roles within our ClickHouse clusters, and you can see that the two roles can only interact with separate parts of the underlying table.
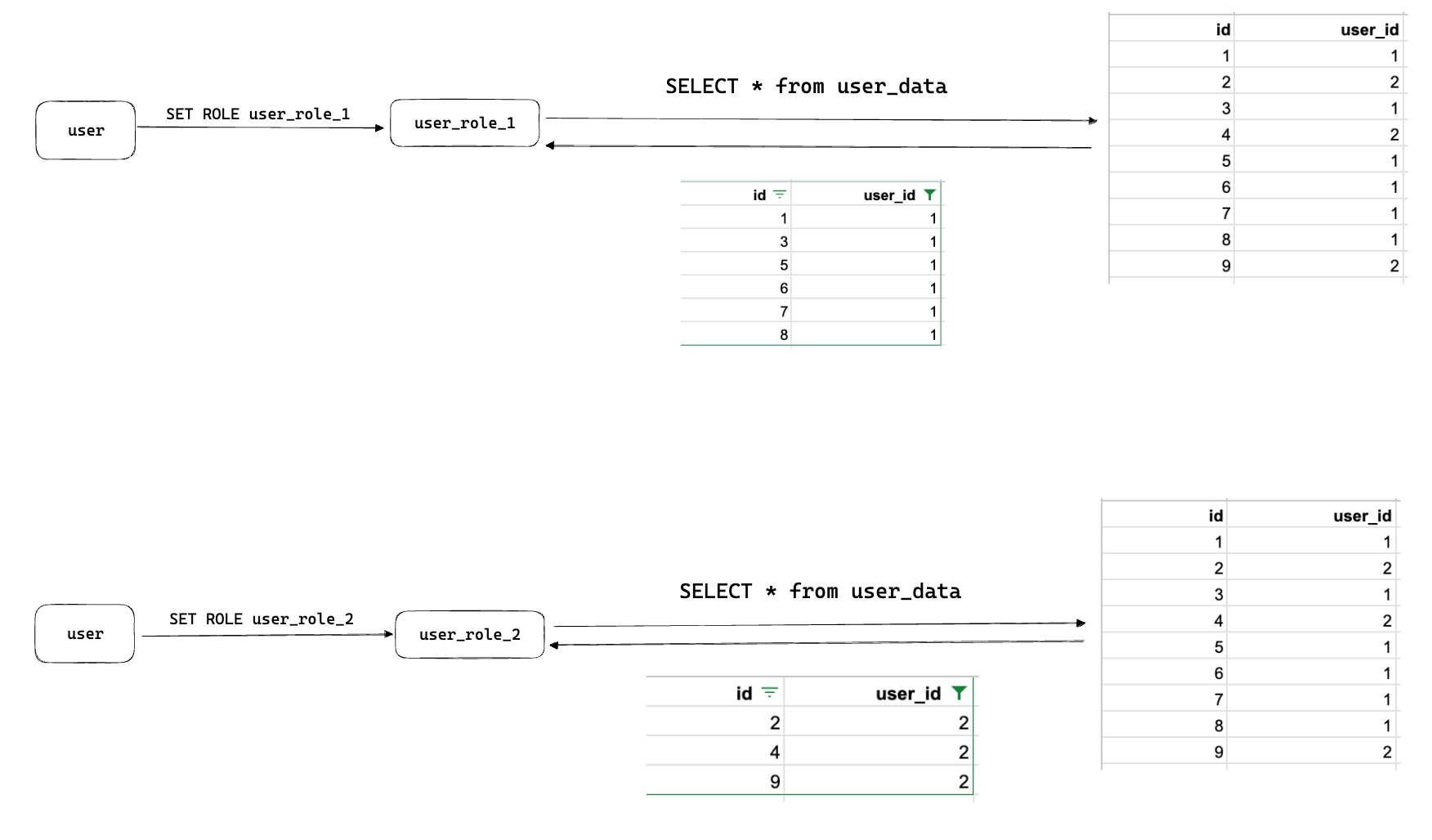
There's a lot of complexity in building role based access control systems, and doing it at the performance and scale required by ClickHouse is not easy.
Bring in the query cache
In 2023 the ClickHouse query cache was deemed appropriate for production workloads in ClickHouse. The goal of the feature is to speed up queries by caching previously run queries so they don't need to be re-evaluated. Depending on your workload the query cache can have an enormous benefit, particularly for driving UIs displaying analytics and dashboards, but ClickHouse's blog on the topic will have more details about using the feature.
Enabling the query cache can be done on a per-query basis by appending settings to end of the query.
SELECT * from user_data SETTINGS use_query_cache = true
Most caches with this function are just big hashmaps where the key is a combination of the query that was run, and the user who ran it. ClickHouse's query cache is no different, with the Key being formed out of the query's parsed AST, and the user_name of whomever ran the query (and some other junk that isn't important for this blog)
QueryCache::Key::Key(ASTPtr ast_, const String & user_name_)
But since user_name is just the user string from above we run into the obvious question of what happens when the same user, using different roles, queries using the query cache. If the query existed in the query cache then user_role_2 might get someone else's data!
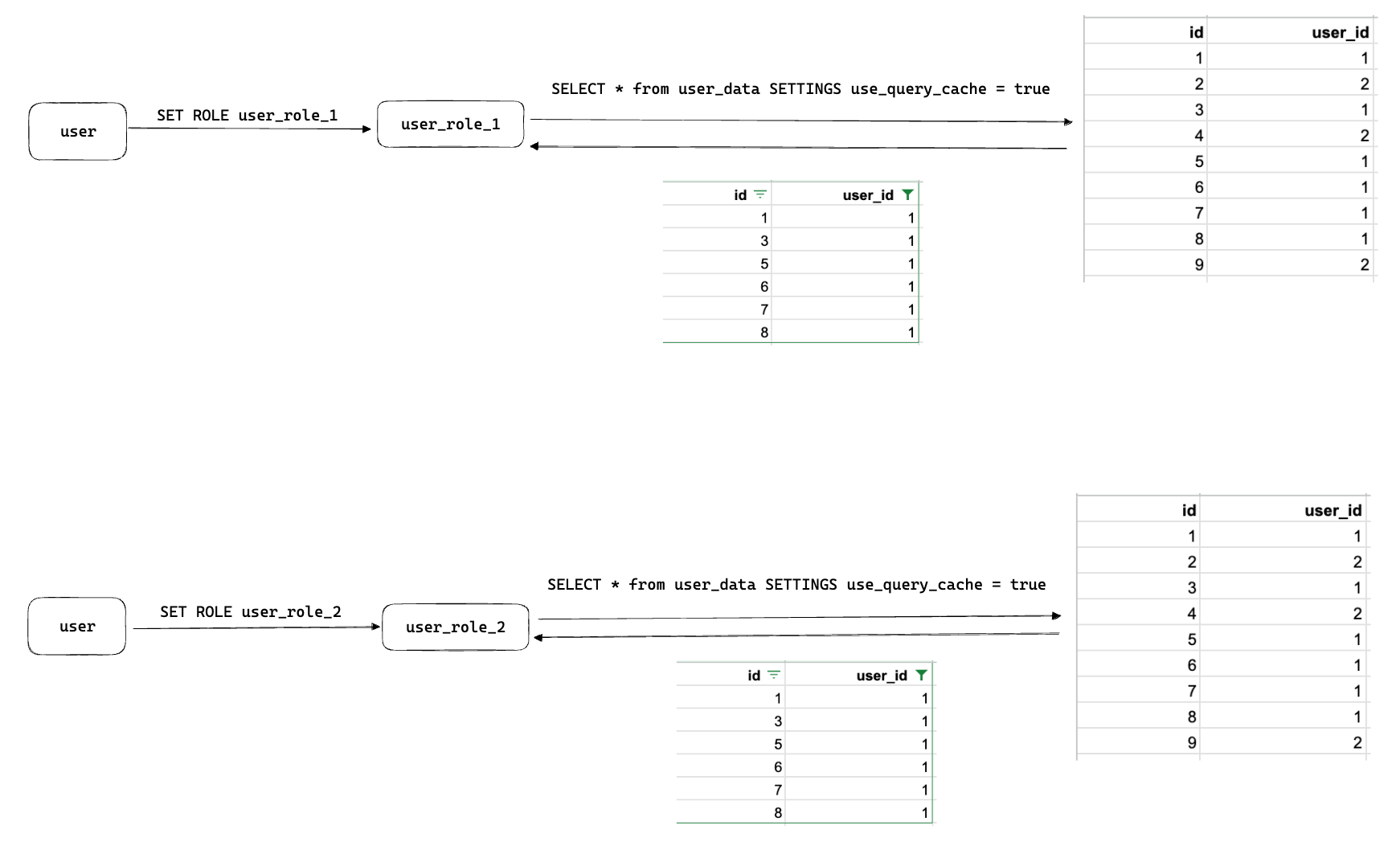
It isn't too difficult to come up with a practical way to exploit this type of issue. Any system using the query cache along with separate roles to safely run queries could be brute forced by spamming commonly run queries.
After we consulted ClickHouse's docs on the topic and noticed that roles weren't mentioned, we felt like we were dealing with something that deserved to be considered a vulnerability. Because we were able to find statements affirming that row policies should be respected, but no mention of roles, it seemed like it might have simply been an oversight.
Finally, entries in the query cache are not shared between users due to security reasons. For example, user A must not be able to bypass a row policy on a table by running the same query as another user B for whom no such policy exists. However, if necessary, cache entries can be marked accessible by other users (i.e. shared) by supplying setting [query_cache_share_between_users](https://clickhouse.com/docs/en/operations/settings/settings#query-cache-share-between-users).
Patching the query cache
After reporting the issue to ClickHouse on Bugcrowd it wasn't long until we noticed a patch for it had been developed, and the implementation passed our eye-test.
The key changes that were made was to first, incorporate the current users and roles into the cache key. This involved updating the way that the cache key was generated, and you'll subtly notice that user_name was updated to user_id.
QueryCache::Key::Key(ASTPtr ast_, std::optional<UUID> user_id_, const std::vector<UUID> & current_user_roles_)
During the query cache lookup, the previous logic only checked to see if the query cache key entry was shared, and if the user_name matched the previous username.
if (!entry_key.is_shared && entry_key.user_name != key.user_name)
After fixing, this line of code was replaced with a more involved verification that enforces the user_id must match, along with the current_user_roles. There's some hairy boolean logic here to handle caches that pre-date this change, but it's nonetheless correct.
const bool is_same_user_id = (
(!entry_key.user_id.has_value() && !key.user_id.has_value()) ||
(entry_key.user_id.has_value() && key.user_id.has_value()
&& *entry_key.user_id == *key.user_id)
);
const bool is_same_current_user_roles = (entry_key.current_user_roles == key.current_user_roles);
if (!entry_key.is_shared && (!is_same_user_id || !is_same_current_user_roles))
This fix also prevents users who are deleted and re-created from accessing their previous cache entries, which is an interesting problem that is noted in the fix's code but we hadn't thought of when we reported this issue.
Preventing this type of issue
This type of bug is my favorite because the bug is easy to understand and fix, but to catch it up-front is extremely difficult. Especially when both features were added at separate times in the last couple of years.
Writing software is hard. In any sufficiently advanced code-base it's difficult, if not impossible, to develop new features while keeping the needs of every other feature in mind. That's the crux of why static code analysis and other types of tools haven't fixed logic flaws.
There's no silver bullet. I've found that the best chance to prevent these types of integration problems are to first develop a deep understanding of the security boundaries of your products and features. Once you know the different security requirements that each component in your system requires you can start to write integration tests that always run and prevent regressions, develop launch checklists, and perform targeted security testing. Hopefully a combination of these activities can prevent the problem.
I'm personally fond of checklists as a pragmatic first step where engineers can consider the security of their work without needing special help from a security expert, once the checklist is made. Unfortunately these preventative activities usually start after problems are discovered so make sure you're being proactive about your product security instead of reactive.
What's next?
RunReveal is currently gearing up for RSA and BSidesSF. We'll be in San Francisco the first week of May to speak at BSidesSF, host a booth at BSidesSF as an emerging tech sponsor, and meet with prospective customers while attending events.
If you'd like to learn what RunReveal can do to help your detection and response program, learn about the ways that RunReveal has completely re-imagined SIEM, or get a free coffee with RunReveal's founders then please let us know
At RunReveal we completely reimagined SIEM from the ground up. We're helping customers handle the enormous scale required to manage their security data, cutting down on false positives, and will help you spin up a world-class detection and response function in minutes.