
Backfill your logs, a just-in-time SIEM when you need one.


Starting today, anyone can backfill logs into RunReveal. Setting up robust logging and monitoring can be a huge hassle, and sometimes it doesn't seem like a priority until something bad has already happened. RunReveal is here to enable you to set up a Just-In-Time SIEM in case you find yourself unprepared for an incident.
Imagine this scenario…
It's Friday morning. You check your email and you have a new report sent to your company's security@ alias. "These are usually just spam" you mutter to yourself, but not this time. The email is from a researcher who found a trivial to exploit SSRF vulnerability in your systems. Using that SSRF they were able to gain temporary AWS role credentials that had full privileges to your AWS organization.
As you start to consider all the different things you need to do, between fixing the bug, investigating if the issue had been exploited maliciously, and looking for other places in your codebase the same bug might exist, you realize "Shoot, I think I have the logs I need, but they are just sitting in a bucket somewhere".
This happens all the time to even the most conscientious security teams. Without having logging, monitoring, or a SIEM already set up an incident like this can make a bad day even worse. Most people will turn to Athena or BigQuery, but with multiple log sources and schemas, paying per query, setting indexes, and partitioning your data you probably won't even be able to start your investigation until that evening if you skip all the other tasks at hand. On top of the delay, paying per query can add up quickly once you start looking for the needle in a haystack of logs.
RunReveal built the backfill feature to help with this exact scenario, so it's never too late to adopt a SIEM.
How to backfill
To backfill logs into RunReveal, you'll first need to create a new "Source" for the type of log you want to backfill. In this case I'm going to set up source to read from an existing bucket that has my Cloudtrail logs.

Once I've created the source and updated the S3 bucket to allow reading / listing of objects from RunReveal according to the docs, at the bottom of the sources page there's a form to initiate a backfill into an existing source. Using the path prefix, you can load logs from a specific time range that you you care about.
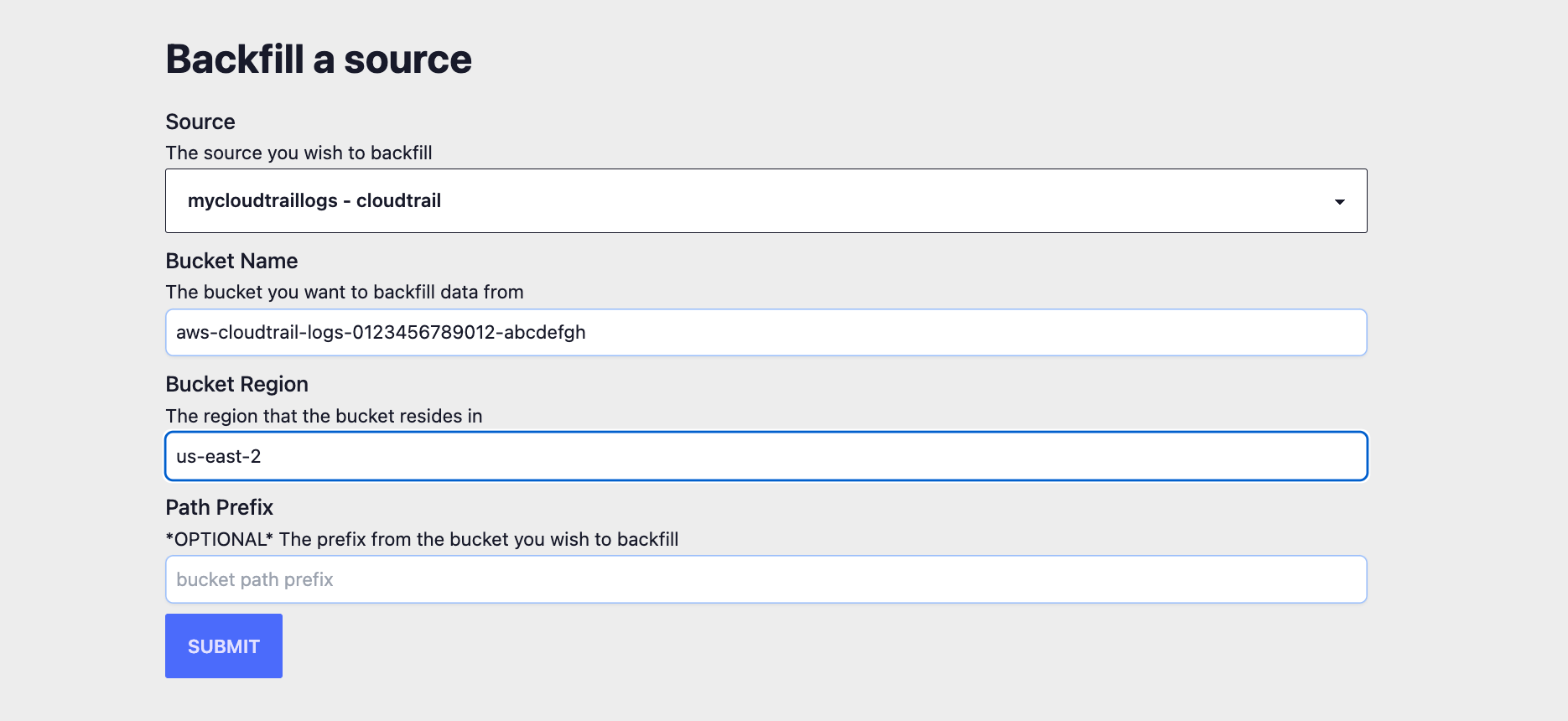
Once the backfill starts, you should see the number of logs begin increasing in your sources list immediately.

As soon as your backfill begins, your logs are searchable, indexed, and available via the search interface through the CLI, our grafana plugin, and the UI. You can start investigating immediately and spelunking through your logs while the backfill does it's work. Even large backfills shouldn't take more than a couple of hours to fully process.

How does it work?
A quick refresher on how RunReveal works. We run the same set of processes across each machine in our infrastructure. Our main data processor is rrq which reads events from a variety of sources and is built on top of kawa.

When reading logs, rrq will get notified of data that needs to be read via an SNS notification that is configured to fire on object creation. The notifications inform us of the bucket name, object key, bucket region, and other basic information needed to download the data. Here's an example SNS notification, note most of the important info is buried in the Message field.
{
"Type" : "Notification",
"MessageId" : "113e595f-dbd0-537e-8a69-043d66a03457",
"TopicArn" : "arn:aws:sns:us-east-2:253602268883:ExampleTopic",
"Subject" : "Amazon S3 Notification",
"Message" : "{\"Records\":[{\"eventVersion\":\"2.1\",\"eventSource\":\"aws:s3\",\"awsRegion\":\"us-east-2\",\"eventTime\":\"2023-08-25T14:31:11.252Z\",\"eventName\":\"ObjectCreated:Put\",\"userIdentity\":{\"principalId\":\"AWS:AROAIZEK622B6YMCISF44:regionalDeliverySession\"},\"requestParameters\":{\"sourceIPAddress\":\"54.248.45.150\"},\"responseElements\":{\"x-amz-request-id\":\"7TYTFZTC5TBZRB65\",\"x-amz-id-2\":\"WDGbqw3qTp81g67hAiwCAJipx6Krn3Y2/94Rfj9Faf8c81Ypim4zAxtvQQpMObJPKJdg7Xv8Ejq886WwOHm2JpTN3zYoncqB\"},\"s3\":{\"s3SchemaVersion\":\"1.0\",\"configurationId\":\"fb296f94-101d-49cc-ad42-f9f23c8c7311\",\"bucket\":{\"name\":\"examplebucket\",\"ownerIdentity\":{\"principalId\":\"A34W79GYXOMSXR\"},\"arn\":\"arn:aws:s3:::examplebucket\"},\"object\":{\"key\":\"AWSLogs/997533895598/CloudTrail/ap-northeast-1/2023/08/25/997533895598_CloudTrail_ap-northeast-1_20230825T1435Z_TyNyyaWY8sliHqMb.json.gz\",\"size\":4314,\"eTag\":\"edb217f6ebf6d8ebb9042b896e20b176\",\"sequencer\":\"0064E8BB2F0AEA9081\"}}}]}",
"Timestamp" : "2023-08-25T14:31:12.421Z",
"SignatureVersion" : "1",
"Signature" : "...",
"SigningCertURL" : "...",
"UnsubscribeURL" : "..."
}
When backfilling, we wanted to ensure that:
- A backfill wouldn't back up our normal queues and delay other customer's logs.
- Autoscaling under increased load would be handled gracefully.
- Customers could start a backfill and start using logs instantly.
- No bespoke infrastructure or processes to manage, only components we had already built.
The rrq process reads from one SQS queue per data source, but isn't limited to reading from only 1 queue per data source. To start implementing backfills we first added a separate backfill queue for each source . This will ensure we won't delay regular ingest of our customer's data by backing up our main ingest notification queues.
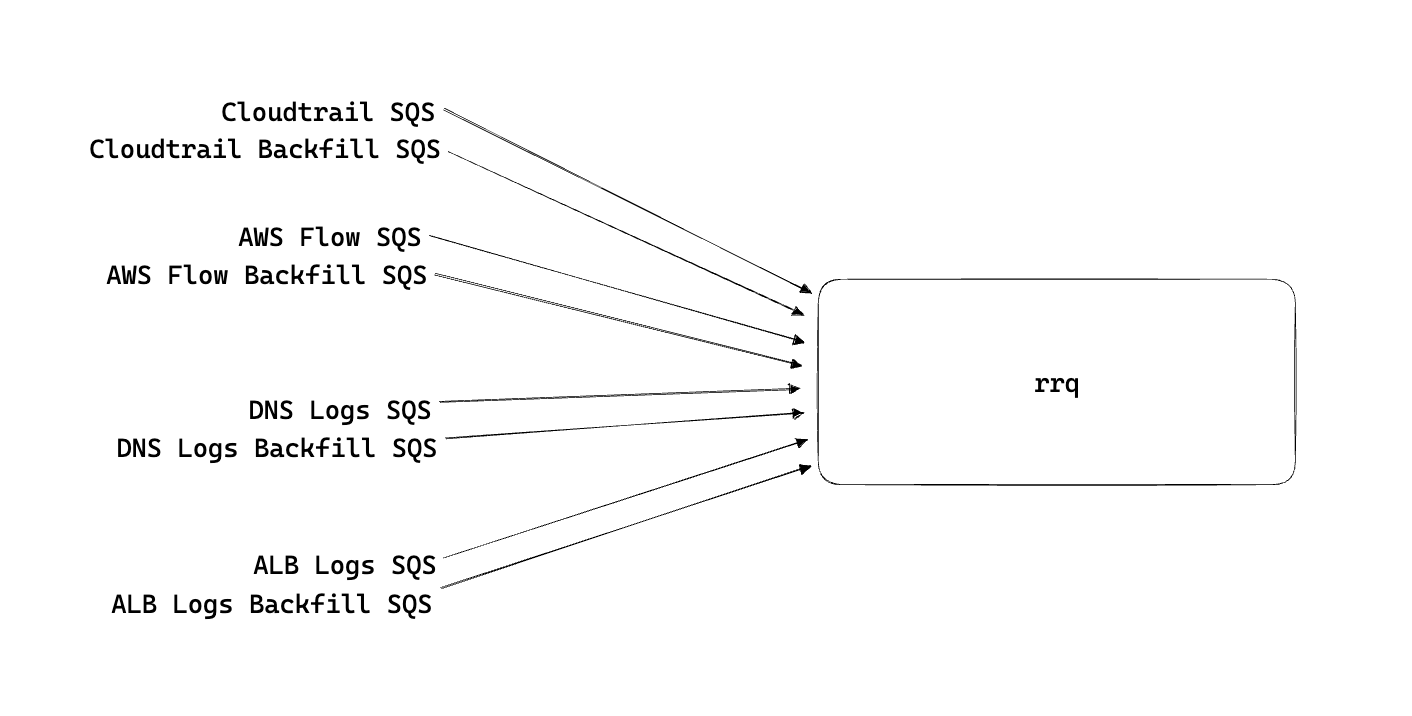
Within our rrq config file, we added new entries to read from the backfill queues and the rrq process will automagically read from each separate queue source.
"sources": [
{
"type": "cloudtrail",
"sqsQueue": "normal_cloudtrail_queue"
},
{
"type": "cloudtrail",
"sqsQueue": "backfill_cloudtrail_queue"
},
...
]
With dedicated backfill queues created, we just needed to implement an API that given a bucket and data type, would create the SNS notification message that we normally receive in our SQS queues, indicating there is data for rrq to download.
The steps to achieve this is straight-forward and involves listing the objects within the bucket prefixes passed to the API, creating one JSON message like the ones above for each object, and enqueuing those messages on the correct SQS queue.
func Backfill(b types.S3BackfillRequest, sc types.SourceConfig) error {
for _, prefix := range b.Prefixes {
// List the objects within each prefix passed
objs, err := ListObjects(b.Region, b.BucketName, prefix)
if err != nil {
return err
}
// Create the messages indicating rrq needs to download data
notifs := FabricateMsgs(b.BucketName, b.Region, objs)
// Enqueue those messages on the desired SQS queue.
err = EnqueueMsgs(notifs, sc)
if err != nil {
return err
}
}
return nil
}
Within the FabricateMsgs function we initialize a large object that mimics the structure of notification messages, but without all of the cruft we don't need.
func FabricateMsgs(bucket string, region string, objs []*s3.Object) []S3Notification {
var notifs []S3Notification
for _, obj := range objs {
var notif S3Notification
arn := fmt.Sprintf("arn:aws:s3:::%s/%s", bucket, *obj.Key)
notif.Records = append(notif.Records, Record{
AwsRegion: region,
S3: S3{
Bucket: Bucket{
Name: bucket,
Arn: arn,
},
Object: S3Object{
Key: *obj.Key,
},
},
})
notifs = append(notifs, notif)
}
return notifs
}When enqueuing those messages, we keep a map of queues and we determine which queue to write to based on the log type that the customer wants to backfill.
var (
queueMap = map[types.SourceType]string{
types.SourceTypeCloudTrail: "https://sqs.us-east-2.amazonaws.com/123456789012/cloudtrail_backfill_queue",
types.SourceTypeALB: "https://sqs.us-east-2.amazonaws.com/123456789012/alb_backfill_queue",
types.SourceTypeFlow: "https://sqs.us-east-2.amazonaws.com/123456789012/flow_backfill_queue",
...
}
)
func EnqueueMsgs(notifs []S3Notification, sc types.SourceConfig) error {
queueURL := queueMap[sc.Type]
for _, notif := range notifs {
buf, err := json.Marshal(notif)
if err != nil {
return err
}
sendMessageInput := &sqs.SendMessageInput{
QueueUrl: aws.String(queueURL),
MessageBody: aws.String(string(buf)),
}
_, err = sqsClient.SendMessage(sendMessageInput)
if err != nil {
return err
}
}
return nil
}
That's all there is to it! Just like that the rrq process can churn through huge datasets without any new complicated code-paths in our data-plane.
What's next?
We hope people will find this useful in their hour of need, or new customers will be able to import the existing logs that already have. To ensure it runs reliably, we can rely on auto-scaling based on queue depth of our backfill queues, but we will need to include status updates so customers can see exactly when their backfills complete and how much data is being read in the near future.
We are going to continue adding features to help our customers understanding their environments, and making the best and friendliest SIEM on the market!
If you have data sources you want us to add support for please contact us, or sign up and start backfilling logs immediately.